
The performance of Conduit data pipelines directly depends on the efficiency of connectors. As the ecosystem of Conduit connectors expanded across various data resources, we recognized the need for a robust and scalable solution that could boost performance uniformly across all connectors. In this blog post, we explore the impact of implementing batching in the Conduit connector SDK, which emerged as the perfect solution promising to elevate the performance of our connectors to the next level.
While our motivation was to enhance the performance of any destination connector, we selected the Postgres connector as a focal point to showcase the results that batching could deliver. Batching unlocked the true potential of the connector, improving the processing rate by a factor of 20. Bear in mind that similar improvements can be expected in other connectors.
Understanding Batching
The efficiency of record processing plays a critical role in the overall performance of data pipelines. Batching is a powerful technique that can significantly improve connector performance. In this section, we delve into the concept of batching, its inner workings, and the benefits it brings to data processing.
What is Batching?
Batching involves grouping multiple data records together and processing them as cohesive units. Instead of handling individual records one by one, batching allows us to bundle operations, such as database queries or API calls, into a single larger request.
The beauty of batching lies in its ability to reduce the overhead incurred by processing individual requests separately. By aggregating multiple requests into a single batch, we significantly reduce the number of round trips between the connector and the data resource, minimizing the latency associated with each operation.
Benefits of Batching
Batching offers wide-ranging benefits:
- Reduced network overhead: Batching considerably reduces the number of network requests, lowering the overall network overhead and enhancing the efficiency of data transmission.
- Improved throughput: Batching enables connectors to process a larger volume of data requests simultaneously, boosting the overall throughput of data pipelines.
- Reduced latency: This one may be counter-intuitive, but batching can actually reduce the latency when the rate of produced records gets closer to the limit of the non-batching approach. Fewer round trips between the connector and the data resource result in a higher throughput thus reducing the average latency.
- Enhanced scalability: By optimizing the processing of multiple records in batches, the connector becomes more scalable as it reduces the pressure on the destination resource.
- Resource optimization: Batching reduces the strain on system resources, allowing for more efficient utilization of server capacity, computing power and network bandwidth.
Versatility of Batching
One of the key advantages of batching lies in its adaptability across various types of connectors and resources. Whether connecting to relational databases like Postgres, NoSQL databases, APIs, or other data systems, batching can be applied as a unifying performance enhancement strategy regardless of the data resource.
Implementing Batching in the Connector SDK
In this section, we delve into the nitty-gritty of implementing batching in the Connector SDK. We will explore the technical intricacies, design considerations, and challenges faced during this process.
No breaking changes
*“Forethought spares afterthought.” -*Amelia E. Barr
When we designed the Connector SDK interfaces, we had the foresight that there would come a time when implementing batching would be crucial for achieving optimal performance in destination connectors. Therefore, we laid the groundwork by preparing the interface to handle batches, even though the SDK initially only provided a single record per batch. This forward-thinking approach allowed us to seamlessly implement batching in the Connector SDK without the need for breaking changes.
The interface draws inspiration from Go's io.Writer and provides developers with a familiar and intuitive way to work with batches. Here's the relevant interface definition:
type Destination interface {
// Write writes len(r) records from r to the destination right away without
// caching. It should return the number of records written from r
// (0 <= n <= len(r)) and any error encountered that caused the write to
// stop early. Write must return a non-nil error if it returns n < len(r).
Write(ctx context.Context, r []Record) (n int, err error)
}This interface makes the Connector SDK responsible for collecting records into batches, allowing the behavior to be centralized and tested without the need to repeat it in individual connectors.
Batching middleware
In the Connector SDK documentation we encourage developers to include the default middleware unless they have a very good reason not to. Most connectors therefore benefit from new middleware as soon as they update to a new SDK version. We used this to our advantage by adding a new batching middleware that enables the batching behavior in virtually all connectors.
Batching strategies
The middleware introduced in the previous section injects two parameters into the connector specifications:
sdk.batch.size- This option sets the maximum number of records in a batch. Once a record is added to the batch and the limit is reached, the whole batch gets flushed synchronously to the destination connector.sdk.batch.delay- The maximum delay before an incomplete batch is written to the destination. The delay is measured from the time the first record gets added to the batch. This option essentially controls the maximum latency added to a record because of batching.
These strategies ensure users can tailor the batching behavior to suit their specific needs and optimize performance accordingly. If you are interested in the internals of these strategies you're welcome to take a look at the batcher implementation.
Transactional integrity and error handling
In Conduit, all records are strictly ordered. This guarantee extends to batches, where records in a batch maintain their order from the oldest (received first) to the youngest (received last). The connector is free to decide if it wants to store all records in a single transaction or treat them independently, however, it needs to write the records in the correct order. This means that, in the event of a failure, a connector can fail to write part of the batch, as long as there's an index that divides the batch into two parts: successfully written records should be to the left of that index, while failed records are to the right.
In case of a failure the connector can return the number of successfully written records and an error. The SDK will positively acknowledge the first n records and use the error to negatively acknowledge the rest. Only if the number of successfully written records matches the size of the batch, is the write considered completely successful.
If the connector follows this behavior, Conduit is able to guarantee the correct order of records in the data pipeline and at-least-once delivery of all records.
Benchmarking using the Postgres Connector
With the batching implementation in place, it was time to put it to the test. We conducted benchmarks using the Postgres connector to evaluate the impact of different batch sizes on throughput and latency.
Configuring the pipeline
We decided to run a simple pipeline that uses the built-in generator connector as the source and the Postgres connector as the destination. The generator constantly produces records as fast as possible, which makes the throughput of the pipeline completely dependent on the throughput of the destination connector.
We tested the pipeline with different batch sizes, from 1 (no batching) to 10, 100, 1,000 and 10,000.
Here is the configuration file for the pipeline:
version: 2.0
pipelines:
- id: generator-to-pg
status: running
connectors:
- id: gen
type: source
plugin: builtin:generator
settings:
format.type: structured
format.options: "id:int,first_name:string,last_name:string"
- id: pg
type: destination
plugin: builtin:postgres
settings:
url: "postgres://meroxauser:meroxapass@localhost:5432/meroxadb?sslmode=disable"
table: "batch_test"
# Tested batch sizes: 1 (no batching), 10, 100, 1000, 10000.
sdk.batch.size: 1000
# Batch delay is not relevant, records are constantly produced and
# flushed before the delay is reached.
sdk.batch.delay: 1s
processors:
# The generator produces a raw key, we use a processor to hoist it
# into a structured payload, needed by the Postgres connector.
- id: hoist
type: hoistfieldkey
settings:
field: "key"We also prepared the table in the target database in advance:
CREATE TABLE batch_test (
id int,
first_name varchar(255),
last_name varchar(255),
key varchar(255)
);Collecting metrics
When running the pipelines we were collecting and monitoring Conduit metrics using Prometheus and Grafana. We mainly focused on the metric conduit_pipeline_execution_duration_seconds. This is a collection of metrics that together represent a Prometheus histogram tracking the duration a single record spends in the pipeline, from the time it is received by the source to the time it is acknowledged by the destination.
We monitored the metric using two Grafana graphs:
- A heatmap showing the end-to-end latencies of records traveling through the pipeline.
- A time series line graph showing the throughput of the pipeline in records per second over time.
If you are interested in graphing these values for your Conduit instance have a look at conduitio-labs/prom-graf, a simple project that provides the necessary services and pre-configured dashboards.
Results
We ran the benchmarks on a 2019 MacBook Pro with a 2,3 GHz 8-Core Intel Core i9 processor and 32GB RAM. Each pipeline ran for exactly 1 minute on a clean slate (fresh database and fresh Conduit instance).
The results speak for themselves: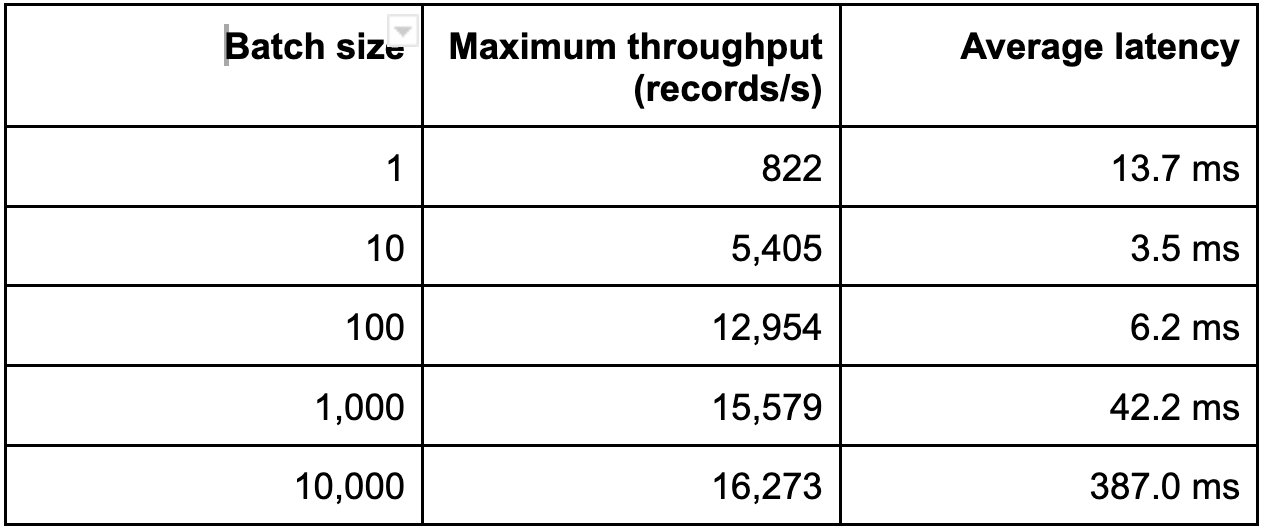
Here is the same data represented in a graph:

Throughput
We can observe the throughput starting at 822 records per second with batching disabled and increasing to over 16,000 records with a batch size of 10,000. That's an increase of throughput by a factor of 20!
The biggest jump in throughput can be seen in the first step when we increased the batch size from 1 to 10. It improved the performance of the pipeline by a factor of 6.5. The next step going to 100 further improved the performance by a factor of 2.4. Further increases of the batch size still had a noticeable effect, although not as extreme as the first two steps.
Latency
The common assumption might be that batching inherently increases latency, as records are held to be flushed together. This holds true when the incoming record stream is relatively slow. However, as the workload increases, the latency can rise sharply when records start waiting on previous ones to be flushed. In such scenarios, batching can actually reduce latency while improving throughput by minimizing these waiting times.
This graph demonstrates when batching can improve the latency:

This is exactly what we observed in our results. Enabling batches with a batch size of 10 dropped the latency from 13.7ms to 3.5ms. Further increases in the batch size also increased the latency, as bigger batches naturally increase the time it takes to collect a batch and flush it. A batch size of 100 still had a lower latency compared to the pipeline without batching, although we observed a sharp increase of the latency for batch sizes 1,000 and 10,000.
Conclusion
The benchmark results conclusively demonstrate that batching plays a pivotal role in improving the performance of our connectors. With larger batch sizes, we achieved substantially higher throughput and in some cases even lower average latencies, which translates into faster data processing overall.
We found that the optimal batch size for significant performance gains was around 100. At this batch size, the throughput showed a notable increase compared to the non-batching configuration (>15x), and the average latency was halved. While larger batch sizes continued to enhance pipeline throughput, they also incurred higher latency, thus the decision to use a higher batch size would depend on the priorities of the specific use case. If higher throughput is more important than low latencies, higher batch sizes would still be applicable.
The decision on what batch size to use is ultimately in your hands as the user. It will depend on different factors like the expected amount of records per second, the size of the records, the spikiness of the load, what latency is acceptable, etc. You need to carefully think about these factors and, if possible, gather actual information about the incoming data stream to make an educated decision about the appropriate batch size.
Final thoughts
Looking back on our decision to implement batching, we recognize that it has positioned the Connector SDK for the future. Batching provides the scalability, efficiency and flexibility needed to handle high-load pipelines. With this feature, we are able to lower the latencies as well as increase the throughput in virtually every destination connector across the board.
We encourage you to try out Conduit and let us know what you think!




