
Let’s be honest, spending tons of time moving data around is not a fun or valuable activity for software engineers. Most of the tooling to solve this problem primarily targets data analysts or data engineers, not software engineers.
Today, the tooling for software engineers is incredibly complex and challenging to operate. For example, we have to install distributed systems with multiple dependencies, which also happen to be distributed systems 🙃 .
Moving data between data infrastructures should be much easier and free. Today, we’re happy to announce that we’re open-sourcing Conduit, Meroxa’s data integration tool built to be flexible, extendible, and provide developer-friendly streaming data orchestration.
Writing software is becoming moredata-centric every day. Software engineers now commonly pull data from all sorts of places from within (or without) their infrastructure to provide data-driven features to their users.
Let’s make that easier.
Getting Started with Conduit
To get started with Conduit, you can head over to ourGitHub releases page and:
- Download Conduit Binary
- Unzip
- Build Pipelines 🚀
If you’re on Mac, it will look something like this:
$ tar zxvf conduit_0.1.0_Darwin_x86_64.tar.gz
$ ./conduitThen, from the very beginning, you’ll be able to open your web browser, navigate to[http://localhost:8080/ui/](http://localhost:8080/ui/) to start building pipelines.
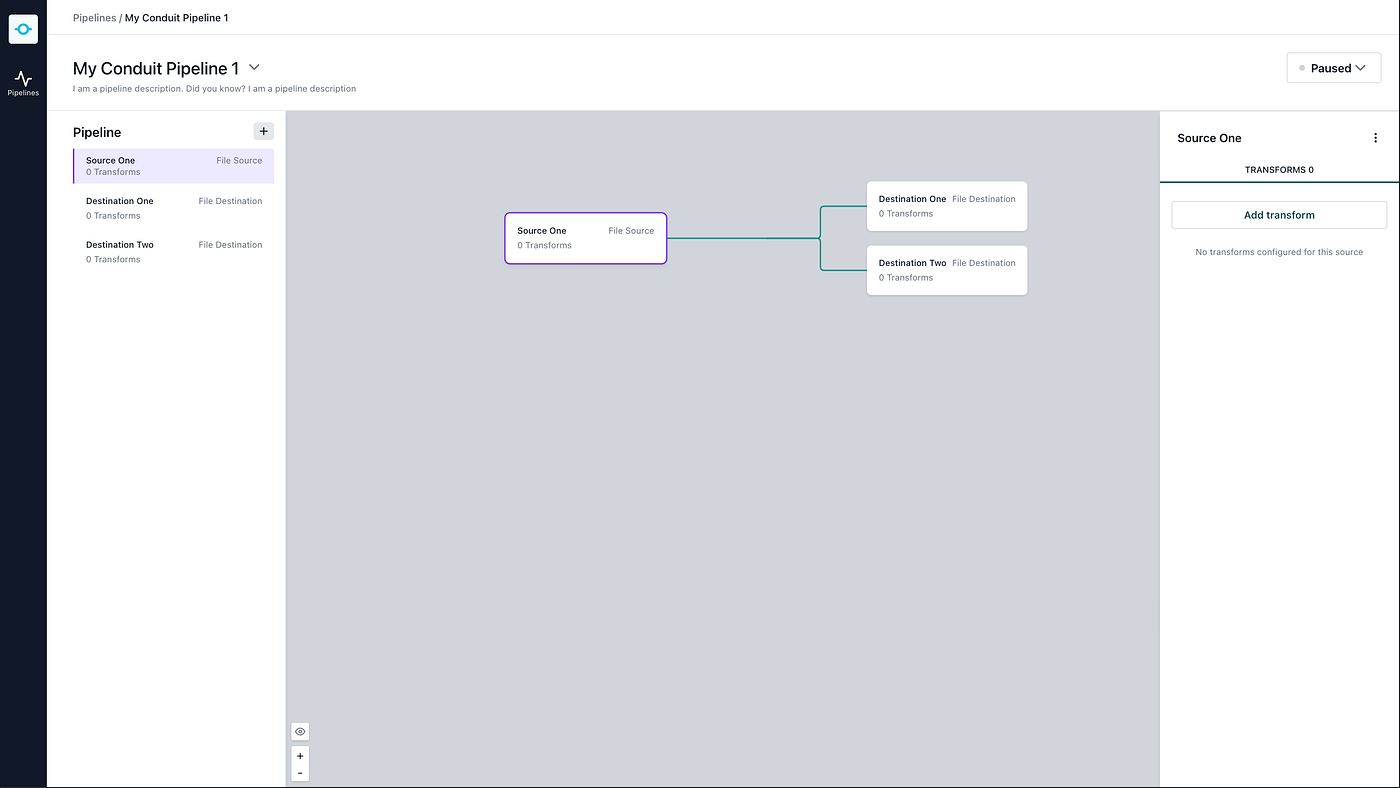
Conduit ships with a UI for local development. Then, once you get data moving, there is much more for you to explore.
Why We Made Conduit?
At Meroxa, our vision is to enable developers to build streaming data applications without worrying about deploying and monitoring complex distributed infrastructure like Apache Kafka and Kafka Connect.
But, to make those applications possible, you’ve got to be able to move between nodes in a directed acyclic graph (DAG) with minimal latency and using as few resources as possible.
Not only that, we needed:
- **Easy deployment:**With a large number of customers moving data within Meroxa’s infrastructure, any efficiencies start to compound, especially when running a managed service. (cough...cough JVM)
- **Allow for DevOps and Monitoring best practices:**We wanted to ship logs straight to Prometheus without dealing with intermediate agents. In the Java world, we would have had to use JMX, which comes with its own set of dependencies and potential failures.
- **An excellent connector developer experience:**Developing connectors should be consistent, straightforward, and familiar with modern languages.
- **A User Interface:**We wanted a baked-in user interface to aid local development. This also makes getting started super easy.
- To control data movement with code: We needed a tool-driven via config files, a REST API, or gRPC. Having the ability to use software to manage your data moment systems offers compelling use cases.
- Be Open Source — Licensing should be permissive (open-source, ftw!)
In the end, we couldn’t find anything that met all of these requirements, so we embarked on creating our own.
From a philosophical perspective, this functionality should be made available to all developers. We should all work toward a future where moving data within production architectures doesn’t prevent data-centric features from being built. Free data integration is what’s going to get us to the next generation of software.
What can you build today?
Today, you can build pipelines that move data from:
- Kafka to Postgres
- File to Kafka
- File to File
- PostgreSQL to Postgres
- PostgreSQL to Amazon S3
We only started with these data sources, but there are many more coming down the pipeline (pun intended). If you have any ideas,we’d love to hear them.
However, even with the connectors, we have today, you should start to think about and build the following use cases:
- Sending messages to and from Kafka to other data stores.
- Storing changes of your PostgreSQL replication log in Amazon S3 for auditing.
- Streaming logs to Kafka.
We are already using this behind the scenes at Meroxa. If you create a pipeline with Meroxa, it’s using Conduit.
What’s Next
We arebuilding Conduit out in the open. It’s an ambitious project, but we think we have something pretty cool. I hope youcheck it out.
Here are your next steps:
- Chat with the Conduit team in theDiscord Community
- Request features/ ask questions about Conduit inGitHub Discussions
- Send bug reports toGitHub Issues.
- Check out theConduit Documentation.
- Show us love onTwitter.



