
Conduit has been a public tool for more than 3 years now. When we first started developing Conduit the goals were clear - make a simple-to-use data streaming tool that "just works". Since we started from scratch, we were following the old advice of "make it work, make it right, make it fast". We focused on getting the functionality right and picked an architecture that gave us the flexibility the project needed at the start, without focusing as much on performance.
After years of developing Conduit and operating it on our platform, running thousands of pipelines, we were finally in a place where we could, without a doubt, tick off the first two. Conduit worked correctly as set out at the start and the code was structured in a way that allowed us to easily extend its functionality. Now we found the time to focus on the last part of the advice - "make it fast".
After benchmarking and profiling the code we quickly identified the bottlenecks in Conduit's internal streaming engine. We realized that a new architecture would not only have a great impact on the throughput but also simplify the code. Win-win!
The Old Architecture: Strengths and Limitations
Let's first give you an overview of the old architecture, why we chose it in the first place and what were its limitations.
Directed Acyclic Graph (DAG)
A data pipeline is in essence a directed acyclic graph (DAG), where data is moving from one or multiple sources through one or multiple processors that process the data towards one or multiple destinations. Now, if we draw such a DAG, we can easily see that each node in the graph receives data from a previous node and passes it on to the next node. Conceptually, this perfectly fits the classic way Go encourages developers to write concurrent code, where each goroutine communicates with other nodes using a shared channel.
Here’s what a DAG could look like in a typical pipeline.
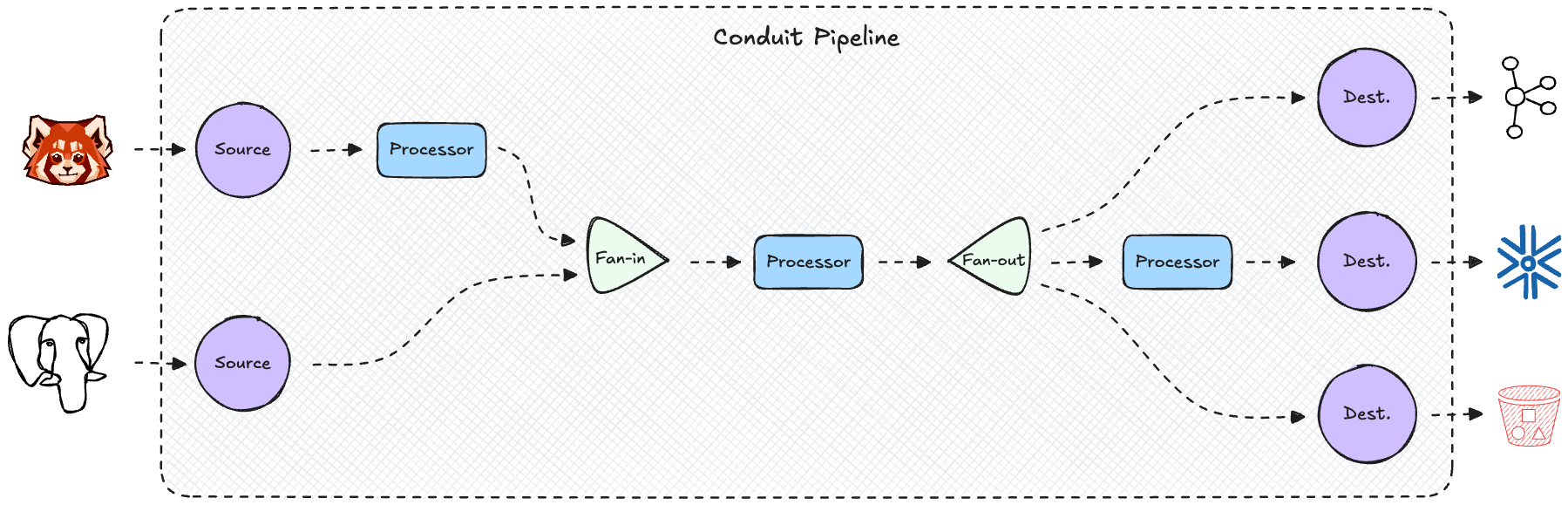
So this is exactly what we modeled in our code. Every node in the DAG was a separate goroutine that was responsible for doing one specific task. The goroutines passed data to each other using unbuffered channels. This software architecture is close to the mental model developers generally use when thinking about a data pipeline. Since we just started working on the project and didn't have a clear idea of all the features we wanted to implement in a Conduit pipeline, this seemed like a straightforward choice. It gave us the flexibility of creating different pipelines by connecting nodes together any way we pleased. In the end, we settled on the Conduit pipeline structure we all know and love today - one or multiple sources at the start, one or multiple destinations at the end, and processors that act on the whole pipeline or on a single source or destination.
The Good
This architecture made it very easy to implement two very valuable guarantees - the ordering guarantee and backpressure. Go channels already guarantee that data written to a channel by one goroutine will be received on the other end in the same order. Since we only ever had a single goroutine writing to a channel and a single goroutine reading from it, the data always flowed through the pipeline and reached the destination in the same order as it was produced by the source.
We also decided to use unbuffered channels. An unbuffered channel can only be written to if there is another goroutine reading from that channel, otherwise the writer is blocked. This essentially means that any node in the DAG can only send data to the next node if the next one is ready to receive the data. This resulted in backpressure being applied over the whole pipeline. The speed of the slowest destination thus dictated the speed of the whole pipeline, since sources would be blocked trying to send data to the next node if the last node (destination) was busy writing a record.
The fact that we used nodes also allowed us to easily implement things like parallel processors and the stream inspector. The basic building blocks did not have to change, instead, we simply adjusted the topology of the pipeline by adding additional nodes or connecting them in a different way.
The Bad
However, there were limitations to the architecture. First, to keep things simple, we made it a rule that nodes only ever operate on a single record. This allowed us to reason about our code and made it easy to make sure all records were accounted for and flushed when a pipeline was stopped. However, this also meant that batching records was off the table. This was the single biggest bottleneck of the old architecture, since processing records and sending them through channels one by one resulted in lots of handovers between goroutines. When profiling the code we noticed that the nodes spent most of the time writing or reading from a channel. Reducing this overhead was a huge opportunity for optimization.
We realized that managing a huge number of goroutines can get out of hand quickly. Edge cases that can happen in a highly concurrent environment can be non-intuitive for humans to figure out and even harder to test and reproduce consistently. Even though each node was a relatively simple building block by itself, the complexity of orchestrating them was that much higher, especially when a node unexpectedly stopped and things had to be cleaned up.
The Ugly
Debugging a pipeline that's composed of dozens of goroutines can suddenly become a day-long task. If you are so lucky that you can reproduce the issue, you still have to find the goroutine causing it. Well, if the cause is a single goroutine, that is. Odds are that the issue is caused by multiple goroutines interacting in a certain way.
And then there are the two worst things that can happen in a concurrent environment, panics and blocks. A panicking goroutine will bring down the whole application, so recovering and converting panics to an error is crucial. This is easily done if you are in charge of spawning the goroutines, but you need to be consistent or use a library like conc to do it for you. Blocking goroutines are harder to prevent. If a bug in the code causes a goroutine to block forever, you can't force it to stop from another goroutine. And the more goroutines you have, the higher the chances of ending up with an uncaught panic or a blocked goroutine.
The New Architecture: Simplicity and Performance
We utilized the lessons we learned from implementing the old architecture, benchmarks and profiles, and decided to implement a new streaming engine, designed with simplicity, performance, and maintenance in mind.
The Worker-Task Model
While the Go community often emphasizes the power of goroutines and channels for concurrent programming, our experience showed that overusing these abstractions introduced overhead that became a bottleneck. Although the node architecture offered flexibility, it didn't meet our performance needs because the pipeline still operated sequentially, which meant that we didn't benefit from parallel processing. Each record had to go through multiple nodes, adding latency and reducing throughput due to the overhead of managing these intermediate steps.
We decided to remove the unnecessary concurrency and embrace a single-threaded approach. This way we gained significant performance improvements while making the code easier to understand and debug. The result is a leaner, faster, and more maintainable engine that retains all the reliability guarantees our users expect from Conduit.
The new architecture operates with a single-threaded worker per source. Each worker executes a sequence of tasks, representing the stages of the pipeline:
- Source tasks: Collect a batch of records from the source connector.
- Processor tasks: Transform, filter, or enrich the batch of records.
- Destination tasks: Send the processed batch to the destination connector.
Unlike the previous DAG-based approach, where records are moved between nodes via channels, the new model processes batches end-to-end within the same worker. This eliminates the overhead of inter-goroutine communication and reduces context switching.
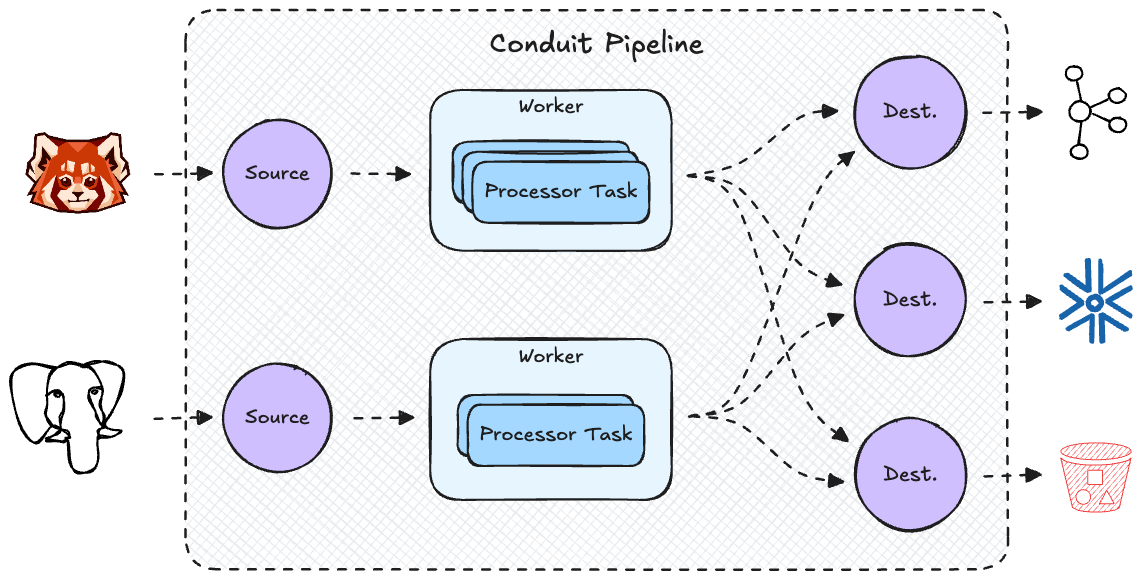
Besides cutting down on goroutines we also introduced the ability to process batches of records, which dramatically decreased the time spent on guiding records through the pipeline, since those operations were now executed only once per batch and not once per record. Note that what we call "batch" in Conduit could be considered a "micro-batch", since the size is very small and it's flushed every few seconds. The purpose is simply to reduce the number of operations per record and the number of round-trips to external systems. Users are in charge of defining the maximum batch size and the delay after which a batch is flushed, so the old behavior of streaming every record separately is still achievable and sometimes even preferable (e.g. to reduce latency in a pipeline that doesn't expect a high load in the first place).
Backward Compatibility and Guarantees
An important goal of the new architecture was to keep the new engine backward compatible and retain the same guarantees that we provided in the old architecture, specifically the ordering guarantee and backpressure.
Given that records from a specific source need to reach the destination in the same order as they are produced on the source, we decided to use a single worker per source to not fall into the trap of having to orchestrate the order across multiple workers. This made it trivial to implement backpressure since a worker is only ever processing one batch at a time, so the source is not able to produce another batch until the last one is processed end-to-end.
However, because we introduced batching, the ordering guarantee was a tougher nut to crack. You have to consider acknowledgments to understand why this was not simple:
- Ordered acknowledgments: Records must reach the destination in the same order as produced by the source. At the same time, acknowledgments must propagate back to the source in order.
- Acknowledgments are done per record: Conduit sends acknowledgments back to the source connector for specific records, not for whole batches, as batches can be partially processed.
- Records need to be end-to-end processed: Only records that reach the end of the pipeline can be successfully acknowledged. "The end of the pipeline" could be the dead-letter-queue (DLQ) or a destination.
To illustrate these challenges, let's dive deeper with an example.
Consider a pipeline with 1 source, 1 processor and 1 destination. The records produced by the source are supposed to contain URLs, which the processor uses to fetch more data and enrich the records.
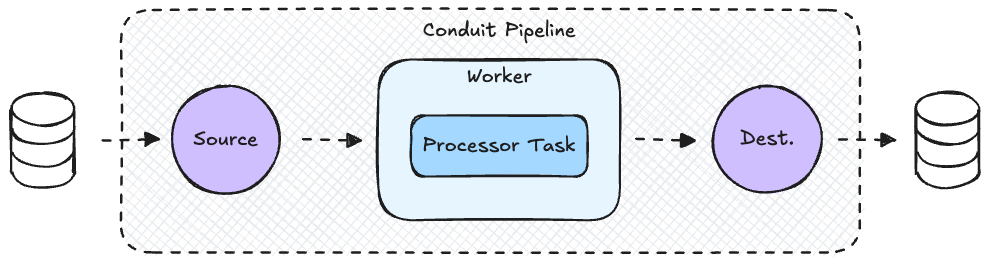
Let's say the source produces a batch of 5 records and the worker supplies them to the processor. The processor processes all records successfully, except the 3rd record, which contains a malformed URL. Now, what should the worker do in this case to correctly honor the ordering guarantee?
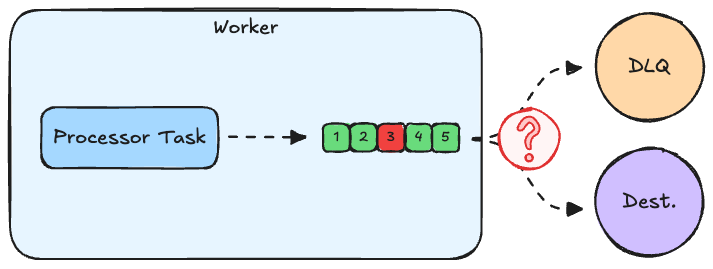
Write to DLQ first
One idea would be to send the 3rd record to the DLQ right away, remove it from the batch, and send the remaining 4 to the destination. However, if the 3rd record is successfully written to the DLQ while the rest fails to be written to the actual destination, the ordering guarantee is violated.
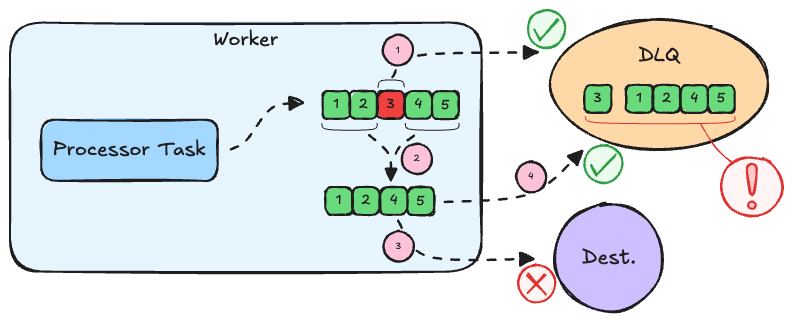
Write to the destination first
What if we remove the 3rd record from the batch and first send the remaining 4 to the destination before sending the 3rd one to the DLQ? Again, the ordering guarantee can be violated if the 4 get successfully written to the destination, but the 3rd record fails to be written to the DLQ. In this case, the pipeline would stop, because the 3rd record failed to be written to any destination as well as the DLQ. The next time the pipeline is started, it would continue from the last acknowledged record. But since we have already written and acknowledged record 5, the pipeline will continue with record 6 and lose 3 forever.
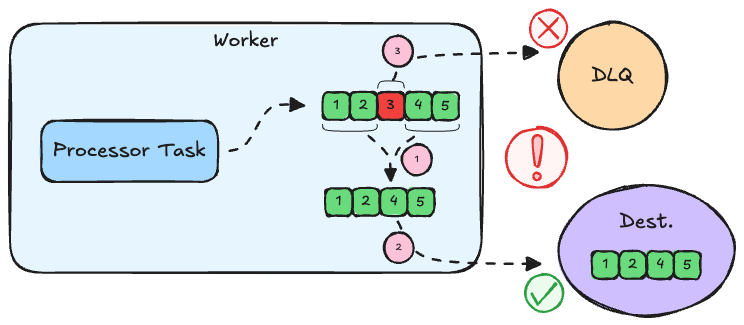
Split batch
The only correct thing to do is to split the batch into separate sub-batches:
- The first sub-batch contains records 1 and 2, which are sent to the destination as a single batch. Only once those are processed end-to-end and acknowledged can we continue to the next record.
- The second sub-batch contains only the 3rd record. The record is written to the DLQ, and if successful, it means the record has reached its end of the pipeline and can be acknowledged.
- Now the remaining records 4 and 5 can be sent to the destination as a single batch. Even if this operation fails, the records can safely be written to the DLQ, without violating any ordering guarantees.
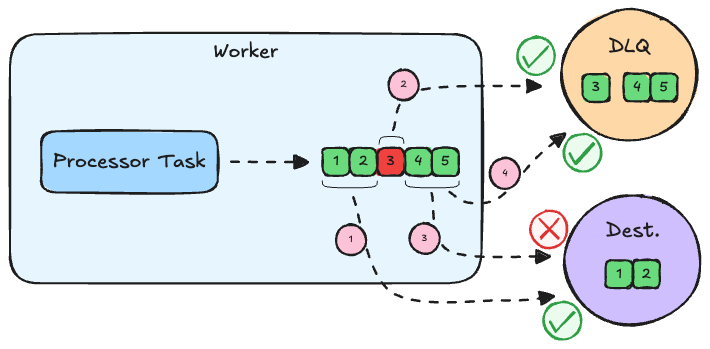
The example can get much more convoluted if you imagine multiple processors that fail to process multiple non-consecutive records in a batch. The generic solution we came up with is splitting the batch into sub-batches of consecutive records that are either all successfully or unsuccessfully processed. This approach allows us to retain the end-to-end ordering guarantee even in the face of failures.
Performance Benchmarks
Benchmark Setup
We tested the performance of the new architecture compared to the old architecture in an end-to-end test using the simplest pipeline you can build in Conduit. The source generates records as fast as possible, while the destination logs them with the level "trace", so the records don't show up in the log (Conduit by default only displays INFO and higher levels). Both connectors are built-in ones which further minimizes the effect of connectors on the test.
Here is the pipeline configuration file we used for our tests:
version: 2.2
pipelines:
- id: benchmark
status: running
connectors:
- id: generator
type: source
plugin: builtin:generator
settings:
format.type: file # take payload from file, to skip generation overhead
format.options.path: ./payload.txt # different payload sizes - 25B, 1kB, 10kB
sdk.batch.size: 10000 # different barch sizes - 1, 10, 100, 1000, 10000
sdk.batch.delay: 0s # turn off time based batch collection
- id: log
type: destination
plugin: builtin:log
settings:
level: trace
We used different scenarios, to get a better overall picture of the performance:
- We tested different batch sizes (1, 10, 100, 1.000 and 10.000) by changing the
sdk.batch.sizefield on the source connector. - We tested different payload sizes (25B, 1kB, 10kB) by adjusting the
format.options.pathand supplying a file of the corresponding size.
We ran all pipelines on both the old and the new architecture, therefore we tested a total of 30 pipelines. While the pipelines were running we were collecting metrics using Prometheus and analyzed them with Grafana. We were specifically interested in the average throughput (messages per second) and the average latency of a message (i.e. how long it takes for a message to flow from the source to the destination).
The tests were executed using Conduit v0.12.3 on a 2024 MacBook Pro with the M4 Max CPU and 36GB of RAM.
Results
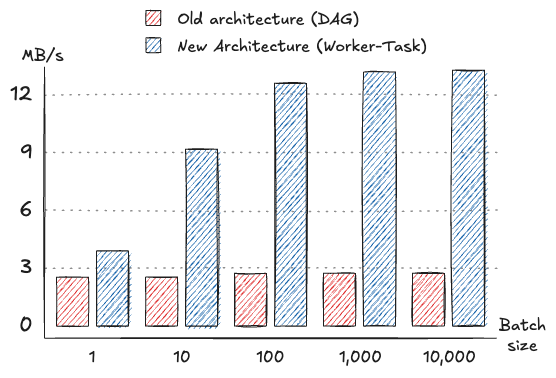
For a payload size of 25 bytes, the new architecture achieved a peak message rate of 569,000 messages per second with a throughput of 13.6 MB/s at a batch size of 10,000. In comparison, the old architecture could only process up to 117,000 messages per second, achieving a throughput of 2.8 MB/s under similar conditions. Latency in the new architecture remained under 1 millisecond for smaller batch sizes and scaled efficiently, reaching 10-25 milliseconds even with a batch size of 10,000. That's half the latency we observed in the old architecture.
Note that we are measuring the throughput based on the raw payload size in the source. Every record has metadata attached, like when it was read, the source connector ID, the source connector plugin name and version, etc. Because the payload size is only 25 bytes, the metadata is much larger than the payload in this scenario. So even though the throughput in terms of MB/s might seem low, keep in mind that the actual message size is much larger, and Conduit is pushing more than half a million records per second through the pipeline.
Testing a more realistic scenario with 1 KB payloads, the new architecture reached a peak throughput of 267.6 MB/s, corresponding to 274,000 messages per second with a batch size of 1,000. This marks a substantial improvement over the old architecture, which peaked at 98,000 messages per second and 95.7 MB/s. Latency remained under 1 millisecond for smaller batch sizes and scaled gracefully to 25-50 milliseconds for larger batches.
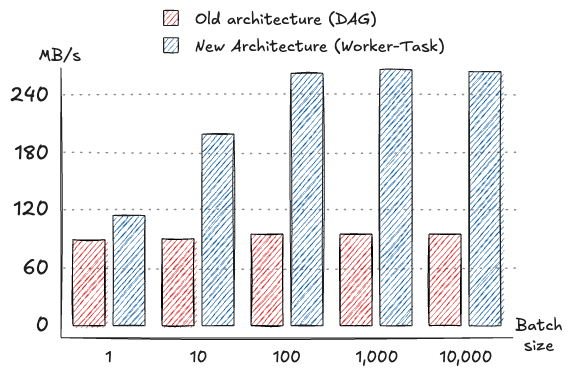
With 10 KB messages, the new architecture delivered a throughput of up to 507.8 MB/s, representing a significant increase from the old architecture's peak throughput of 380.9 MB/s. The message rate in the new architecture rose to 52,000 messages per second at the highest batch size tested, compared to 39,000 messages per second in the old architecture. Curiously, the old architecture achieved a better throughput in the case of no batching (batch size of 1), although the difference was negligible and was made up by higher throughputs when batching was enabled.
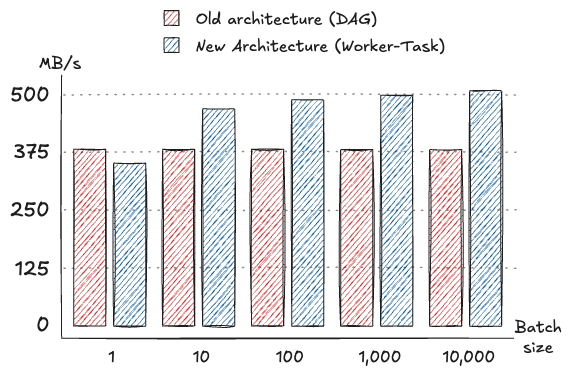
Overall, the new architecture outperformed the old one in almost all tested scenarios, particularly excelling in high-throughput and low-latency applications. These improvements demonstrate the effectiveness of the architectural changes in enhancing performance across varying message sizes and batch configurations.
Conclusion: The Future of Conduit
The results of our evaluation highlight the substantial performance gains achieved by the new architecture. We are pleased with our decision to simplify and improve Conduit's internals which resulted in an increase in throughput of over 5x for certain scenarios, while further reducing the end-to-end latency. The changes allow Conduit to address even more demanding real-world scenarios.
The rollout of the new architecture is controlled via a feature flag which should ensure a smooth transition while allowing early adopters to test its capabilities in their own environments. We encourage you to experiment with this new architecture and provide feedback:
$ conduit run --preview.pipeline-arch-v2One exciting area for future exploration is the possibility of parallelizing workers by loosening ordering guarantees, such as partitioning the record stream and processing it with multiple workers. This approach could further increase the throughput for workloads that don't demand such guarantees. Open a GitHub discussion or join us on Discord and let us know if this is something you would like to see next! Follow us on Twitter, LinkedIn, and YouTube for more insights and updates!




