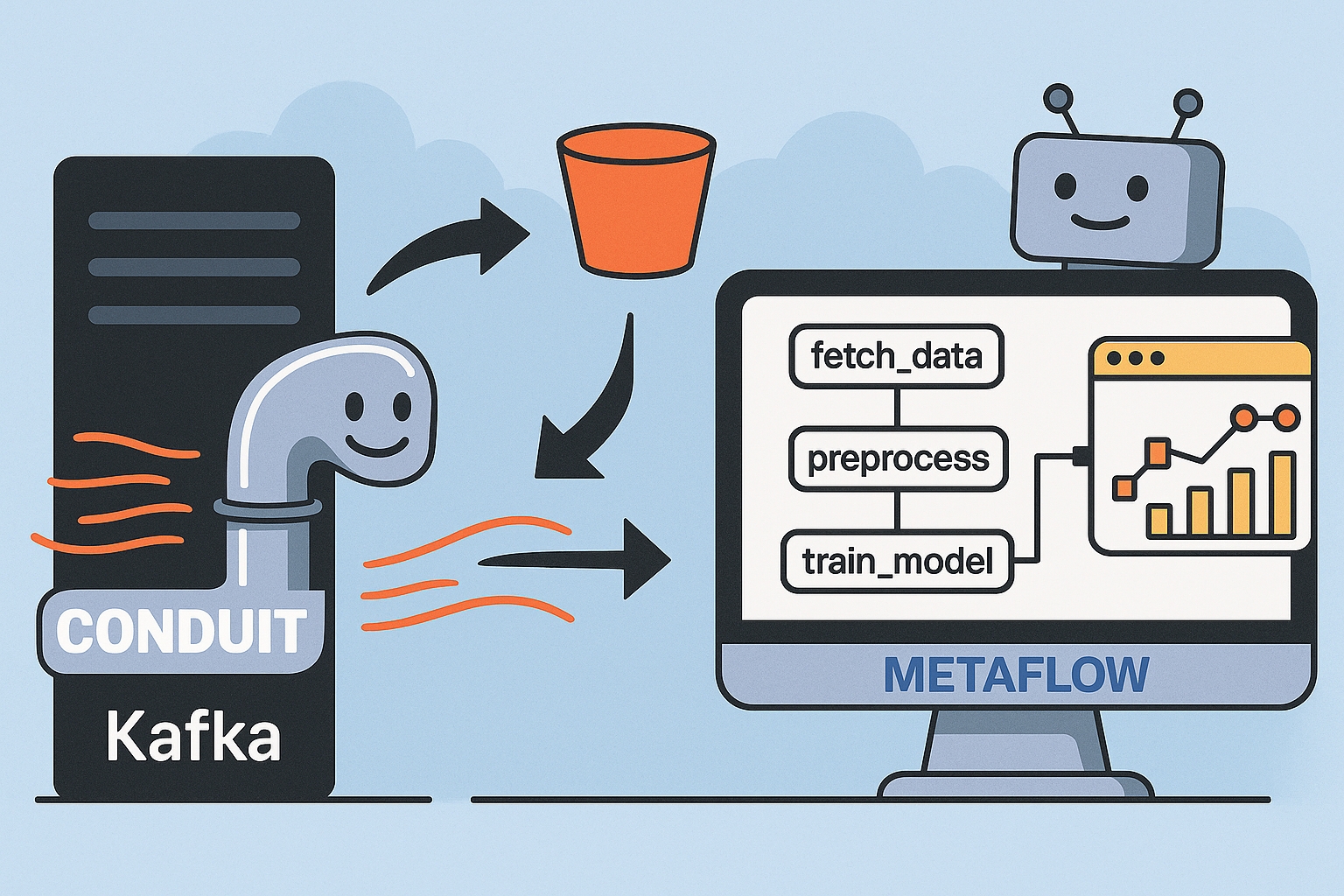
If you’ve used Metaflow to orchestrate data science workflows, you know how powerful and intuitive it is. But feeding those workflows with real-time data? That’s where things can get messy—especially if you’re stitching together multiple tools just to get data from Kafka into S3, or wrangling batch jobs to keep everything in sync.
This post shows you how to simplify that entire process using Conduit. Pairing Conduit with Metaflow gives you an efficient, maintainable, and reproducible data pipeline that flows from raw event to insight.
How Conduit Fits In
Metaflow handles orchestration: steps, parameters, and execution. What it doesn’t do is handle real-time ingestion. That’s where Conduit comes in. It connects to live sources (like Kafka, Postgres, MongoDB) and pushes cleaned, structured records to sinks like S3 or cloud databases. It’s lightweight, fast, and written in Go.
Together, they form a clean architecture:

What You’ll Need
You’ll want:
- Python 3.7 or higher
- Docker
- AWS CLI set up (for S3 or Batch)
- Conduit v0.14.0 or later
- Metaflow v2.7.0 or later
Set Up Kafka Locally
If you don’t already have a Kafka cluster, here’s how to spin one up for testing:
docker run -p 9092:9092 apache/kafka:4.0.0Getting Conduit Running
Install Conduit (choose what works for you):
macOS:
brew tap conduitio/conduit
brew install conduitLinux / other:
curl https://conduit.io/install.sh | bashTo verify:
conduit versionUse the conduit init command to scaffold a pipeline in your preferred directory. Replace the default YAML file in the /pipelines directory with the below YAML file.
version: "2.2"
pipelines:
- id: orders-pipeline
status: running
connectors:
- id: kafka-source
type: source
plugin: kafka
settings:
servers: "localhost:9092"
topics: "orders"
groupID: "conduit-orders-group"
- id: s3-destination
type: destination
plugin: s3
settings:
aws.bucket: "my-data-bucket"
aws.region: "us-west-2"
aws.accessKeyId: "<ACCESS_KEY>"
aws.secretAccessKey: "<SECRET_KEY>"
prefix: "orders/"
sdk.batch.delay: "10s"Then launch Conduit with the below command:
conduit runBuilding the Metaflow Flow
Once Conduit is writing events to S3, your Metaflow script can take it from there.
from metaflow import FlowSpec, step, Parameter
import boto3, json
class OrdersFlow(FlowSpec):
s3_bucket = Parameter('s3_bucket', default='my-data-bucket')
@step
def start(self):
self.s3 = boto3.client('s3')
objs = self.s3.list_objects_v2(Bucket=self.s3_bucket, Prefix='orders/')
self.files = [o['Key'] for o in objs.get('Contents', [])]
self.next(self.preprocess)
@step
def preprocess(self):
self.data = []
for key in self.files:
content = self.s3.get_object(Bucket=self.s3_bucket, Key=key)['Body'].read()
records = json.loads(content)
self.data.extend(r for r in records if r.get('status') != 'cancelled')
self.next(self.train)
@step
def train(self):
import pandas as pd
df = pd.DataFrame(self.data)
self.model = 'model-artifact'
self.next(self.evaluate)
@step
def evaluate(self):
self.metrics = {'accuracy': 0.95}
print(self.metrics)
self.next(self.end)
@step
def end(self):
print('Done')
if __name__ == '__main__':
OrdersFlow()Running Everything
Start Conduit:
conduit runRun your flow:
python orders_flow.py run --s3_bucket my-data-bucketAdd --with batch if you’re scaling via AWS Batch.
Pro Tips
- Monitor Conduit at
http://localhost:8080/metrics - Use the built-in dead-letter queue for bad records
- Validate schemas upstream to catch issues early
- Git-track your pipeline YAMLs and Metaflow scripts
- Explore 100+ Conduit connectors beyond Kafka and S3
If you're building data pipelines with Metaflow, integrating Conduit is a no-brainer for real-time data ingestion. With hundreds of available connectors, it's the perfect companion—lightweight, blazing fast, and production-ready out of the box. Start using Conduit today and experience how seamlessly it transforms your streaming data workflows.




