
Who should read this?
Developers who build and/or manage data integration systems. It will be of specific interest to those working with real-time data pipelines, Kafka Connect, and managed streaming services.
Overview
Conduit is an open-source project to make real-time data integration easier for developers and operators. This article is broken into roughly the “Why” and the “How” behind Conduit.
- Why bother creating “yet another” data project?
- Why should WE build it?
- How is Conduit different than Kafka Connect?
Why bother creating “yet another” data project?
We could have simply written another blog post about the many frustrations of working with Kafka Connect for data integration, but we felt it was better to be part of the solution. So, we built and open-sourced a project; a project that we use at Meroxa, that embodies the software development principles we have learned and live by. I will get into some of those principles and the thoughts behind the project in this post.
The project is named Conduit. While Conduit is not simply a Kafka Connect replacement, many of its features were informed by frustrations with Kafka Connect.
Apache Kafka does a great job at being the backplane, but the business value and where more developers spend their time is with the connectors.
We believe the data connector space is in need of some rethinking and innovation. We want to make connector development better suited for developer velocity and operational best practices.
We are not alone in the belief that this space is ripe for innovation. Jay Kreps (co-creator of Apache Kafka) has mentioned the innovations still needed in the connector space in his recent Keynote and in tweets like this one.
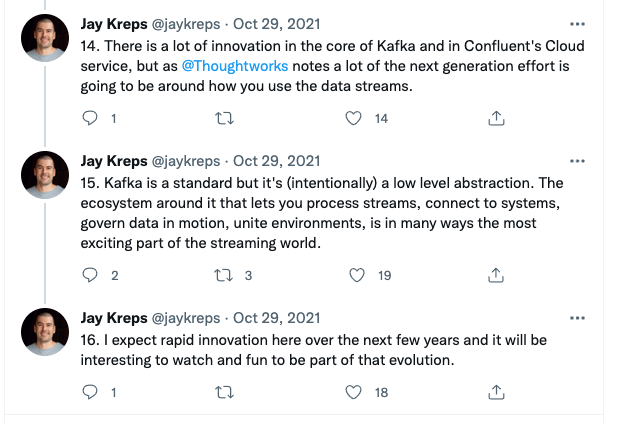
Why should WE build it?
We are a group of developers that have spent our careers developing software for large-scale deployments such as Heroku. Most of the software services/platforms we have worked on in recent years have been in the context of building and managing data services such as Apache Kafka and Kafka connectors.
In that time, we have learned many things about what works well and what leads to issues when developing and supporting large-scale systems. The good news is that most aspects that make a large system easier to tame also cascade down to making a small system pleasant to work with as well. While the opposite is not true.
One benefit in the world of software is that developers have collectively spent a lot of time working out effective methodologies. We have aspirations like “Optimized for Developer Happiness”. Many of those methodologies have influenced and helped us build better software at Meroxa. Such concepts as Agile and 12 Factor Apps have created certain expectations when working on projects and what a “good” project looks and feels like.
With those concepts as a background context, and years of working with Kafka Connect, we decided that we needed a better way to solve data integration problems. A way that adhered to our expectations of maintainable software services. While some concepts are just baked into the project because they are baked into the Meroxa DNA, below are some worth highlighting because they directly contrast with Kafka Connect.
How is Conduit different than Kafka Connect?
Easy local development
Kafka Connect requires a lot of setup (e.g. Apache Kafka, Zookeeper etc) to get to a point of doing development or even “kicking the tires”. It is a very time-consuming development life cycle. Attempting to quickly iterate on code or test things in isolation is very frustrating or impossible. In addition to that, because of all the external dependencies, you may end up with a mismatch between your local setup and what is actually in production or another developer’s environment.
Conduit addresses these issues in a few ways.
- A single Go binary with no external dependencies. Download, run it, get going. No additional infrastructure needed.
- A built-in Web UI. When you run that binary you can access the Web UI and try out configurations with very little upfront knowledge. Allowing you “play” with it out of the box.
- SDK to simplify the connector development and testing. (Discussed later)
- Easy, isolated local testing and test data generation. (Discussed later)
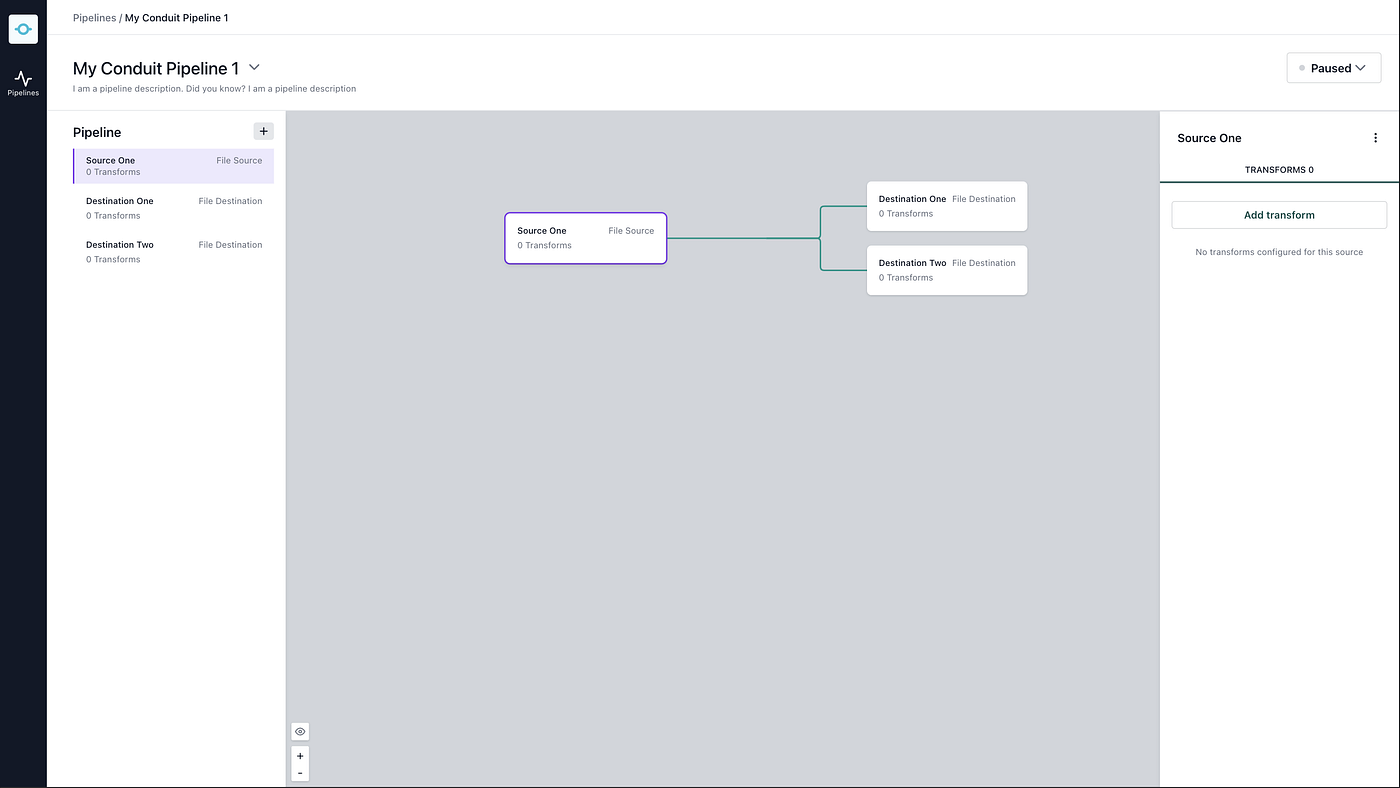
SDK to speed up development
Starting to develop connectors with Kafka Connect is confusing and complicated. You are not encouraged when at every turn the documentation implies that dragons are around the corner and you should just pay to have the connectors handled for you. Can’t we just have an SDK?
We are working on a SDK to make it easy for you. Since our work is “in public”, you can keep an eye on what we are up to.
Connector development is language agnostic
Kafka Connectors are very Java-centric. While you can shoehorn other language support into working, it is not the suggested path and can be painful to maintain and not performant.
Conduit connectors are plugins that communicate with Conduit via a gRPC interface. This means that plugins can be written in any language as long as they conform to the standards-based interface.
Standard API Protocols
Conduit supports gRPC and REST for its management, making it easy to manage with software at scale. Plugins utilize gRPC for data movement and soon it will support the Kafka Connect API as well.
We believe gRPC is the best choice for streaming data APIs. In addition to the benefits of using gRPC for data movement, a large number of community members, projects, programming languages and platforms supported make it a perfect choice for a data project such as Conduit.
In contrast, Kafka Connect uses a custom binary protocol for data and a REST API or java property file for configuration. What this means is that client libraries have to be built and maintained as separate projects that are only useful in the Kafka ecosystem. We will also support the Kafka Connect API to allow you to migrate over existing connectors.
Testing
Testing a Kafka connector requires a lot of infrastructure, visibility is poor, is too prone to misleading errors and generating test data is a pain. Instead of iterating on your code, you feel like you are testing a whole collection of infrastructure you have cobbled together, that may not look like production anyway. So, what were you really testing?
Testing with Conduit — since the connector and the dependencies are decoupled you can test your changes in isolation from the environment. We have created a test data generator and data validator to save you from wasting time trying to create test data to verify your connector is working.
Free and Open
Many Kafka Connectors can not be used by us at all. The limitations on the licenses create situations where you are either locked into the Confluent platform to continue use or in other cases you may be compliant but then as your business grows and involves you unknowingly move into a violation. Many developers experienced the pain with the license shift that Confluent made a few years ago. It sucks to find yourself in that situation. We don’t want that to happen to you.
Conduit is free to use and open source. The license is permissible and encourages developers to utilize and get value from it in their projects. We are strong believers in the value of standards and open source and that we should not be creating situations for lock-in or crippling projects and use cases.
Monitoring
Kafka Connect uses JMX for metrics. We found this to be cumbersome to work with and required additional setup to get metrics into our metrics platform.
Conduit supports sending metrics to Prometheus right out of the box. Prometheus is our preferred metrics platform as well as most developers we have heard from.
Go vs Java
Kafka Connect is built with Java. For our use case, building a multi-tenant platform that leverages Kafka Connect wasn’t economical. Each provisioned connector took up a ton of memory, sometimes in excess of 1GB. If the usage isn’t consistent, you end up with a bunch of provisioned resources that didn’t have a lot of utilization.
Go uses very little resources, compiles to a small deployable binary, has a fast startup/shutdown time, is very stable, very performant and has a large community of projects and support.
Conduit leverages Goroutines that are connected using Go channels. Goroutines can take up as little as 2kB of memory. These basic functions can run simultaneously and independently, making multiple processes very efficient on multi-core machines. Unlike Java threads that consume large amounts of memory, Goroutines, which are used instead of threads, require much less RAM lowering the risk of crashing due to lack of memory.
The small binary size and resource usage provide a variety of benefits. At the large scale, say, If you are building a managed service like us, small memory use, faster boot times, minimal dependencies, small file size, etc translate into actual dollars saved on resources as well as a better user experience. On the small side of the scale, it means you can deploy to even a Raspberry Pi or to places we have not yet considered. But, even for just local development, it means getting up and going and productive quickly.
There are good reasons for Go becoming the language of choice for infrastructure and operation services such as Kubernetes, Terraform, Docker and others. Conduit is built to fit well into that ecosystem, which means better integration and support going forward. The value of a strong community is hard to overstate.
Easy Transformations
Kafka Connect requires you to write transformations in Java and implement a pile of files and functions via a confusing process with little help. It is more complicated than it needs to be. Transformations are widely needed in data pipelines by people even if they don’t build connectors. Transformations should be approachable and easy.
In Conduit, transformations are written in JavaScript. JavaScript is one of the most widely known development languages. Most developers already have to know JavaScript even if they also use another language as well.
Pipeline Centric
Kafka Connect is connector-centric which puts data transformations etc in the background and ties them to the specific connectors, this is problematic because we want to build pipelines, not just connectors. The goal is easy pipelines for real-time data. When you think in terms of pipelines you also make different choices for things like transformations. For example, in the Kafka Connect world the transformation only sits between the source and destination.
Conduit decouples where the transformation sits allowing you to transform from a source and or into a destination. Meaning that your pipeline can take into account how data enters and leaves it as different operations.
Conduit considers pipelines the primary goal and the architecture reflects that.
Ready to get started with Conduit?
Stay up to date with what we are working on, check out the Github Project board.
Review the documentation at the main website as well as the github repo.
Find out how to contribute.
Install Conduit by following the installation guide.
Easily migrate from Kafka Connect
Conduit will support the Kafka Connect API. This will allow you to bring your existing connectors.
Do you have feedback?
What are your struggles with data integration?
What are we missing?
What would you add to the requirements list?



