In today's data-driven world, building and working with data products can be challenging. It requires profound technical knowledge and may even demand an infrastructure overhaul of existing systems. Meroxa’s code-first approach and infrastructure abstraction are key to effectively leveraging your existing infrastructure and engineering team. This can simplify complexity, promote efficiency, reusability, and customization.
In this blog post, we will explore how Meroxa's data platform can enhance your experience when working with Confluent. By utilizing a code-first approach and infrastructure abstraction, we can significantly shorten your investment time from months to minutes and boost the value of your existing investment.
Code-first approach
Taking a code-first approach allows data stakeholders to build upon their established knowledge and collective expertise. Meroxa's Turbine framework is designed with developers in mind, providing a rich local development experience that enables the best practices of software engineering processes and workflows. It allows unparalleled customizability and flexibility when working with Confluent, without the need for deep technical expertise.
Lower the bar to entry and fast start: One of the main benefits of using Meroxa with Confluent Cloud is that it enables your existing teams to rapidly adopt Confluent and Kafka technologies without extensive training or external support. Meroxa simplifies the process of building stream processing applications. For example: (1) developers working with familiar languages and tooling, (2) simplifying the environment setup, (3) logging and monitoring can be implemented with the tool of your choice, (4) using a software workflow for building and testing the application eliminates needing to develop your own. This allows the focus to be working with the data rather than on the underlying complexities of your data infrastructure.
Leverage your existing SDLC workflow and tooling: Meroxa enables you to leverage your existing Software Development Life Cycle (SDLC) workflow and tooling while offering ease of scalability, multiple environments, Git support, CI/CD integrations etc. Meroxa developer workflows that have been refined over years through software engineering best practices, provide tooling and support often missing in today's data projects. With Meroxa you can establish enterprise-wide best practices with Confluent. This increases collaboration and efficiency while maintaining the flexibility and customizability necessary for success in data engineering tasks.
Choose any language: Developers can create stream processing applications and pipelines using their programming language of choice (Python, Go Lang, Javascript, Ruby, etc.), while taking advantage of existing libraries and packages within those languages. By empowering developers with familiar languages and tools, a code-first approach fosters efficiency, reusability, and customization, maximizing the potential of the developer team and saving time and resources.
Infrastructure Abstraction
Infrastructure abstraction is a key feature of the Meroxa Data Platform, streamlining complex data technologies and making them more accessible.
No rip and replace; sits alongside your existing infrastructure: Typically, integrating new data tooling can be disruptive and costly as it requires the development team to re-engineer their data processing pipelines, to learn new programming paradigms, and to adjust their monitoring and management practices. Meroxa sits seamlessly integrates with all your current systems. The resource catalog abstracts the complexities and idiosyncrasies of the supported resource types and presents a simple, unified way to consume data from and/or push data to the resource via a common name.
Allows your team to focus on driving business value: By adopting a code-first approach, Meroxa simplifies the connection process to various resources, supporting the connection of Confluent streams to any destination and vice versa. This freedom of connectors and rapid development capabilities enable developers to deploy fully functioning, production-grade data products from what was months before to minutes. Once resources have been onboarded, they are made available for use via friendly names, with unnecessary implementation details such as connection strings, authentication mechanisms, connector configurations, data formats, and connectivity details abstracted away. This lowers the barriers to entry for building data streams, allowing any data stakeholders to efficiently utilize the data, without the complexities of the given resource.
Automates the operation of the underlying infrastructure: Meroxa automates the management of underlying infrastructure, making it easier for developers to focus on their core tasks. Meroxa provides end-to-end automation, handling everything from packaging user-defined custom code to deploying it any cloud or on-prem. Meroxa provisions and configures the required connectors, integrates them with the custom code to create a seamless system. As traffic patterns fluctuate, the platform intelligently scales function nodes to accommodate changes in demand. Furthermore, Meroxa's self-healing capabilities ensure that any issues with components are promptly addressed, maintaining the stability and reliability of the system.
Meroxa + Confluent = More Value, Less Investment and Months to Minutes
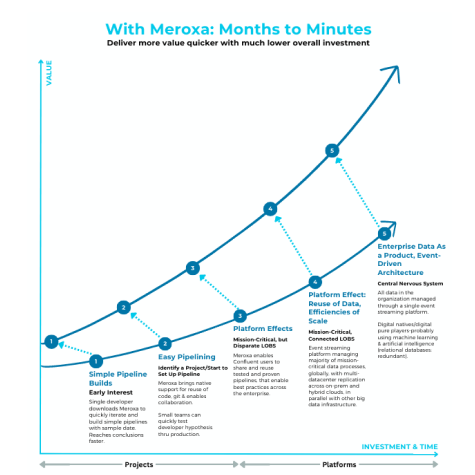
Confluent provides a framework for data in motion, and the partnership with Meroxa helps engage business developers with self-service capabilities that boosts the value of the solution and potentially greatly reduces the investment time from months to minutes. Please see the illustration below. Meroxa’s approach generates greater value for Confluent clients with much less investment in much less time.
Confluent Cloud and Meroxa users do not have to deploy and manage the infrastructure for the stream processing application, allowing developers to build faster pipelines, without having to first solve infrastructure complexities. Meroxa offers a native integration into Confluent Cloud, not just self-hosted Kafka, allowing any data stakeholder to work effortlessly with Confluent Cloud.
Additionally, Meroxa enables streaming data into Confluent from any source, sending data from Confluent to any destination, and working with Confluent data in any format.
Confluent time to value curve
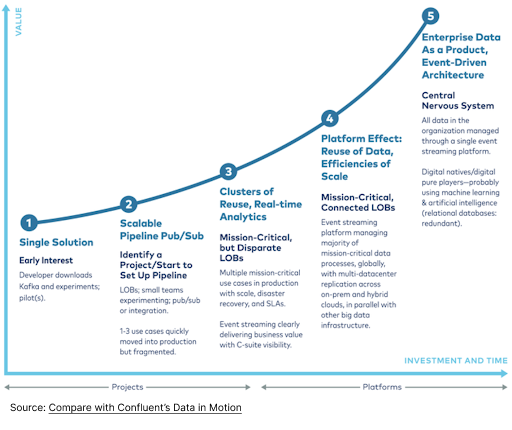
Confluent time to value accelerates with Meroxa**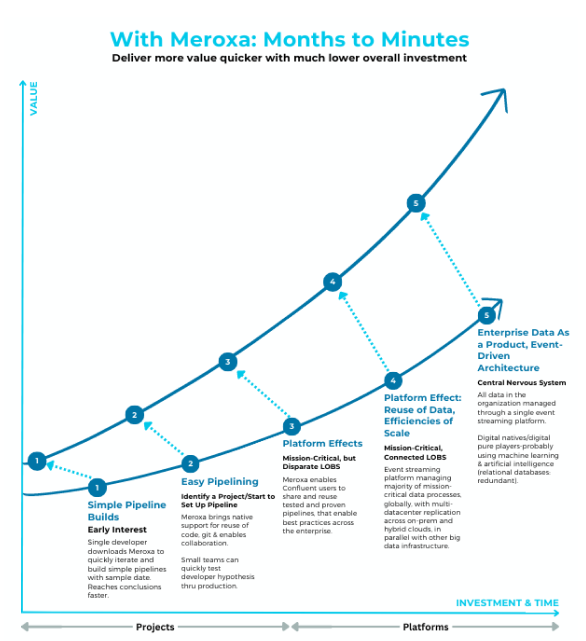 **
**
Simple pipeline builds
Meroxa enables developers to quickly iterate and build simple pipelines by providing a rich local development experience allowing developers of any skill level to test out their hypotheses on data projects, reducing the complexity of working with data.
By allowing users to "sample" Confluent Streams, developers can rapidly local test on new data before committing to larger initiatives. This approach enables organizations to conclude faster on which projects to invest time and resources into, essentially allowing them to test before investing at speed.
Easy Pipelining
Meroxa brings software engineering best practices such as native support for Git and collaboration tools, allowing organizations to extend their software development processes and workflows to encapsulate data engineering.
Moreover, users can integrate packages and custom code modules, allowing for simple reuse of code within the organization and use of external 3rd party modules. By providing these features, Meroxa enables Confluent users to increase collaboration and efficiency, while maintaining the flexibility and customizability necessary for success in data engineering tasks.
Platform Effects
Meroxa enables Confluent users to reuse tested and proven departmental pipelines at an enterprise-wide level, follow enterprise-wide best practices, and benefit from CI/CD integrations and consolidated monitoring of pipelines. The platform also offers ease of scalability and multiple environments (development, testing, staging, and production) that are designed to serve specific purposes.
Enriching real time data streams without Meroxa Turbine
To enrich real time data in Confluent without Meroxa would require Kafka Streams or ksqlDB to implement your stream processing logic.
Kafka Streams: With Kafka streams, you would typically write a Java or Scala application using the Kafka Streams library. In your application, you would define your processing logic, for example: joining the source topic with other topics containing enrichment data, or filtering and aggregating the data. Additionally, you need to deploy the application to a suitable environment, and once it's deployed, you must set up logging and monitoring as well. Furthermore, you would also need to establish a workflow for building and testing the application.
ksqlDB: With ksqlDB, you would write a series of ksqlDB statements to define your stream-processing logic. This includes creating streams and tables, performing joins between streams and tables, filtering, and aggregating data.
Using Kafka Streams or ksqlDB for enriching real-time data streams can present challenges, depending on your use case and team expertise:
- Steep Learning curve: Both Kafka Streams and ksqlDB have a steep learning curve, especially for those who are new to Kafka and stream-processing concepts. Developers need to familiarize themselves with the libraries and APIs, as well as the concepts of stream processing, such as windowing and stateful processing.
- Language limitations: Kafka Streams only allows applications to be written in Java or Scala, which may not be ideal for teams with expertise in other programming languages. While ksqlDB offers a more accessible SQL-like language, it may still require some knowledge of the ksqlDB-specific syntax and features. Moreover, there are limitations to using SQL, as certain tasks cannot be accomplished using this language alone. For example, if you need to interact with a third-party API for data enrichment, or import a specific package to perform image manipulation, SQL would not be sufficient. In such cases, developers must resort to alternative approaches to address these complex requirements.
- Complexity: Implementing stream-processing logic using Kafka Streams or ksqlDB can be complex, particularly when dealing with stateful processing, joins, and windowing operations. This complexity may lead to a longer development cycle and increased potential for errors.
- Scalability and performance: Ensuring that your Kafka Streams applications or ksqlDB queries scale well and perform efficiently may require additional expertise in tuning and optimizing Kafka and the underlying infrastructure.
Enrich real time data streams with Meroxa Turbine
To enrich real-time data using Meroxa’s Turbine framework is simpler. You would simply connect your data streams and implement processing logic in the language of your choice. When implementing the processing logic, you can leverage libraries, packages and APIs you are already familiar with and that have been rigorously tested by millions of software developers.
Here’s a simple example of enriching a data stream using Turbine JavaScript where we convert temperature values from Celsius to Fahrenheit in a stream of weather data:
processDataStream(records) {
records.forEach((record) => {
// Use record `get` and `set` to read and write to your data
const temperatureCelsius = record.get("temperature_celsius");
if (temperatureCelsius !== undefined) {
const temperatureFahrenheit = (temperatureCelsius * 9/5) + 32;
record.set("temperature_fahrenheit", temperatureFahrenheit);
}
});
return records;
}Here is another example of enriching a data stream using Turbine Python using the datetime package, where we prepend a timestamp to each line of a log file:
import datetime
def prepend_timestamp(records: RecordList) -> RecordList:
for record in records:
try:
payload = record.value["payload"]
# Prepend timestamp to each log line
log_line = payload["log_line"]
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
payload["log_line_with_timestamp"] = f"{current_timestamp} {log_line}"
except Exception as e:
print("Error occurred while parsing records: " + str(e))
return recordsThese are just two examples of how Meroxa makes it effortless to work with Confluent data streams using various languages. The possibilities are vast, limited only by your imagination.
Conclusion
Meroxa brings the best practices of software development for data to any environment without bias. Meroxa’s unique and disruptive approach with code-first and infrastructure complexity abstraction has been shown to greatly speed up the value of Confluent with a significant reduction in investment and time - months to minutes. The one example provided was for Confluent, but the same would apply for other key components of your existing architecture: cloud or on-prem, data-in-motion, data lakes and migrations.
To learn more about how Meroxa can help transform your data strategy, schedule a call with our team of experts.




