We're thrilled to unveil the latest version of Conduit! This update, Conduit 0.9, marks a significant milestone in our journey, offering more flexibility and power in data processing than ever before. The development of this release focused on incorporating valuable user feedback, particularly around enhancing processor functionality, to provide a seamless and more efficient experience.
Elevating Data Processing with Advanced Processor Capabilities
In previous versions of Conduit, manipulating records was confined to our built-in processors or custom code within the pipeline configuration file, using a JavaScript processor. This approach, while functional, was not the most user-friendly or flexible. Taking your feedback to heart, we've completely overhauled our processor framework in Conduit 0.9, introducing support for standalone processors. This update opens up new possibilities for data manipulation, allowing you to write custom processors in the language of your choice, thanks to our new support for Web Assembly (WASM) processors.
Introducing Web Assembly Processors for Flexible Data Processing
The flexibility to process data with Web Assembly Processors is a game-changer. For instance, utilizing Go with our new conduit-processor-sdk allows for unprecedented adaptability in processing methods. However, the choice of language is yours, with options like C#, Rust, or Kotlin—all compatible with Web Assembly. For a deeper dive into implementing standalone processors, our "How it works" guide provides comprehensive insights.
Example: Creating a Simple Processor in Go
Below is a straightforward example of a Go-based processor. This custom processor adds a processed field to each record, showcasing the ease of enhancing data with Conduit 0.9.
//go:build wasm package main import ( "context" "github.com/conduitio/conduit-commons/opencdc" sdk "github.com/conduitio/conduit-processor-sdk" ) func main() { sdk.Run(sdk.NewProcessorFunc( sdk.Specification{Name: "simple-processor", Version: "v1.0.0"}, func(ctx context.Context, record opencdc.Record) (opencdc.Record, error) { record.Payload.After.(opencdc.StructuredData)["processed"] = true return record, nil }, )) Compiling our New Processor
After writing your processor, a simple compilation step prepares it for integration into your Conduit pipeline. The process involves setting specific environment variables for the Go compiler to target WASM. GOARCH=wasm GOOS=wasip1
GOARCH=wasm GOOS=wasip1 go build -o simple-processor.wasm main.go Once compiled, your simple-processor.wasm is ready to be deployed within Conduit by copying to the ./processorsdirectory next to our conduit binary.
Using our new processor in a pipeline
Utilizing the new processor involves referencing it within your Conduit pipeline configuration, as demonstrated in our example layout.
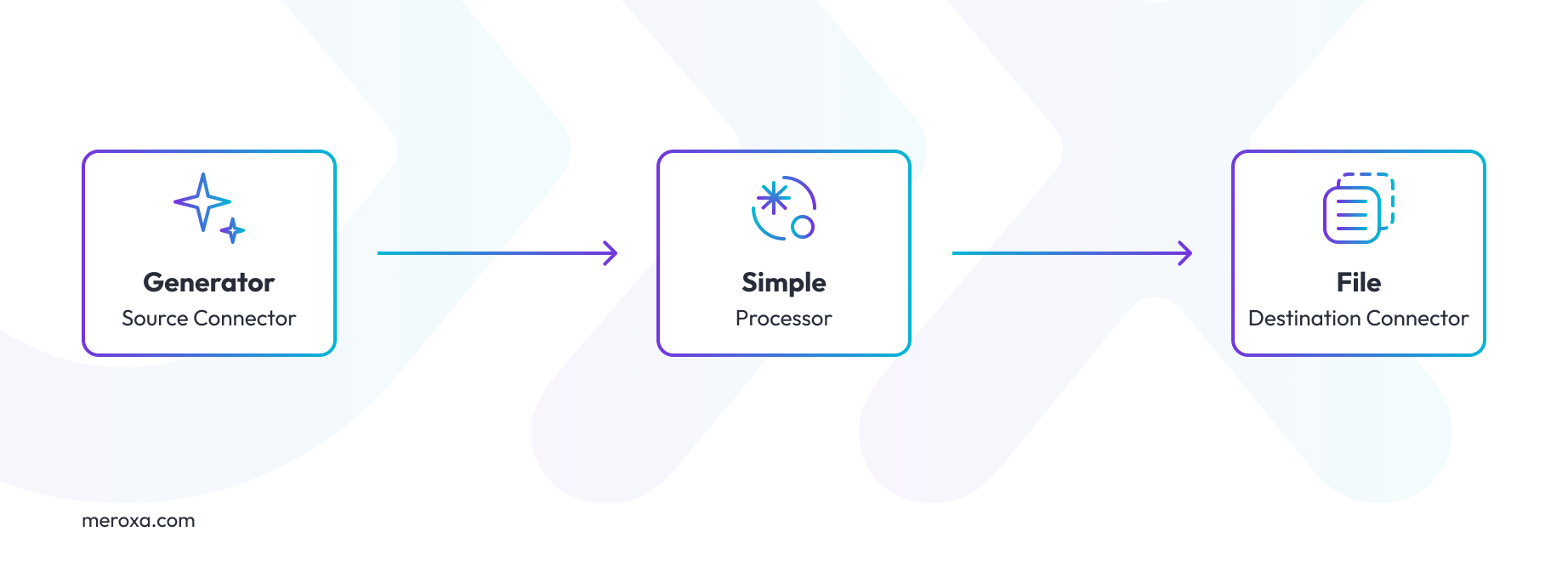
We’ll have the generator connector create records with the form:
{ "addr": "string c5c5d54b-e380-48e0-b24b-444b760a66f3", "id": 1884616843, "name": "string 246def2a-ac48-416c-b3e7-01fcb77c52a2", "zip": "string 2f1f462e-1dfa-4066-a1d7-03370227d672" } Our processor will add a new processed field and then we’ll write that out to a file.
Here’s the Conduit pipeline configuration file for actually creating the pipeline in Conduit.
version: 2.2 pipelines: - id: gen-to-file status: running description: "A demo pipeline with wasm processor" connectors: - id: source-generator type: source plugin: builtin:generator name: gen-source settings: recordCount: '3' format.type: structured format.options: id:int,name:string,addr:string,zip:string - id: example.out type: destination plugin: builtin:file settings: path: ./example.out processors: - id: add-processed-field plugin: standalone:simple-processor You can see the new processor referenced in the processor's section of the pipeline.yaml
processors: - id: add-processed-field plugin: standalone:simple-processor When we start Conduit and check the ./example.out file can see the processed records with the newly added "processed" field.
Not Just Standalone: Improvements to Built-in Processors
The introduction of standalone processors isn't the only highlight of Conduit 0.9. We've also made substantial enhancements to our built-in processors, making them more robust and user-friendly.
Exploring the Enhanced Built-in Processors
Here’s an example of a pipeline that uses two built-in processors. One processor removes a field and the other adds metadata to the record.
version: 2.0 pipelines: - id: gen-to-file status: running description: "A demo pipeline with two built-in processors" connectors: - id: source-generator type: source plugin: builtin:generator name: gen-source settings: recordCount: '3' format.type: structured format.options: id:int,name:string,addr:string,zip:string - id: log type: destination plugin: builtin:log processors: - id: remove-zip plugin: builtin:field.exclude settings: fields: ".Payload.After.zip" - id: metadata-processed plugin: builtin:field.set settings: field: .Metadata.processed value: "true" When we run the pipeline and check the Conduit logs there are three records printed. Our generator is creating records with id, name, addr, and zip fields but at the end of our pipeline, you can see that the record doesn’t have the .Payload.After.zip field. Additionally, there’s now a processed field in the .Metadata
{ "key": "ZGIwYzBlMTQtMDY4Yy00MTQ3LWExOWUtYjBmMGYwMjc1OWUy", "metadata": { "conduit.source.connector.id": "gen-to-file:source-generator", "opencdc.readAt": "1711053477220315000", "opencdc.version": "v1", "processed": "true" }, "operation": "create", "payload": { "after": { "addr": "string 6932464d-d940-4e27-8139-f0175289fd24", "id": 843620792, "name": "string 549efa80-62f4-465d-9399-0129607fa40f" }, "before": null }, "position": "MzYzY2RlZTItZTlmNi00NWE4LWE2MDUtOGE0MGU5M2U1YmVk" } Just by themselves, our built-in processors provide a powerful set of primitives you can use to create sophisticated data processing pipelines.
Get Started with Conduit 0.9
We invite you to experience the advancements in Conduit 0.9 firsthand. Our getting started guide makes it easy to set up Conduit on your machine, allowing you to explore the new processor capabilities and more.
We Value Your Feedback
The new standalone processor support in Conduit 0.9 represents a major step forward in our commitment to improving data processing ergonomics. We're eager to see the innovative ways you'll utilize these capabilities.
Your feedback is crucial to us. Whether it's through posting issues, sharing thoughts in discussions, or connecting with us on Discord or Twitter, we're all ears.
For a comprehensive overview of all the new features and improvements, don't forget to check out the full release notes on the Conduit Changelog.




