
Data drives modern business success, especially in machine learning (ML). But deploying a model just once isn't enough anymore. Today's dynamic environment requires continuous learning, real-time decision-making, and automated feedback loops—core elements of MLOps (machine learning operations). This post shows you how to build a continuous MLOps pipeline using Meroxa for real-time data ingestion and stream processing, paired with Databricks for model development, deployment, and monitoring. You'll learn how to create a high-performing, low-latency ML pipeline that evolves automatically with your data.
What Is MLOps?
MLOps (Machine Learning Operations) is the practice of creating repeatable, scalable processes for developing, deploying, and maintaining machine learning models. It applies DevOps principles—like continuous integration (CI), continuous delivery (CD), and infrastructure as code—to the machine learning lifecycle. This encompasses everything from data collection and feature engineering to model training, validation, deployment, and monitoring.
Most organizations start with pilot ML projects where data scientists build models offline, test them in staging, and hand them to engineering teams for deployment. However, as ML initiatives become mission-critical, managing data pipelines, versioning models, and monitoring performance grows increasingly complex. MLOps provides the framework to address these challenges.
Importance of Real-Time Feedback Loops
Traditional ML pipelines are batch-oriented: data is collected in large chunks, processed offline, and used to retrain models periodically—often monthly or weekly. However, industries like finance, e-commerce, ad-tech, and IoT require near-real-time decisions. Even a few hours' delay can mean missed revenue opportunities or undetected critical events like fraud.
A real-time feedback loop enables models to learn continuously from new data and update their parameters automatically. Combined with robust streaming pipelines and well-orchestrated MLOps practices, real-time feedback helps your models:
- Adapt to changing market conditions or user behavior rapidly.
- Reduce error rates by incorporating the latest ground truths.
- Uncover new patterns or anomalies that weren't visible during initial training.
- Provide immediate insights for operational teams and stakeholders.
In short, real-time MLOps is about transforming continuous data flows into continuously improving models.
Meroxa for Data Ingestion and Stream Processing
Meroxa is a real-time data platform that simplifies the creation and management of streaming data pipelines. It offers connectors for a wide range of data sources—databases, SaaS applications, event streams, and more—enabling users to ingest data seamlessly. Through its intuitive interface and APIs, Meroxa streamlines the complexity of moving data from point A to point B without requiring heavy, hand-crafted ETL processes.
Key capabilities include:
- Managed Connectors: Pre-built connectors for popular data systems (e.g., PostgreSQL, MySQL, MongoDB, Kafka, Salesforce).
- Real-Time Transformations: The ability to process, filter, and enrich data on the fly as it moves through the pipeline.
- Low-Code/No-Code Approach: Users can design pipelines with minimal code overhead, making real-time data movement accessible to a broader team.
- Event-Driven Architecture: Helps ensure that new data is ingested and processed as soon as it’s available, ideal for use cases demanding low latency.
Why Meroxa Is Ideal for Real-Time MLOps
Machine learning pipelines need continuous, reliable, and high-quality data. In a continuous MLOps scenario:
- Data Volume and Velocity: ML pipelines often deal with large data streams—clickstream data, sensor readings, transaction logs—that are best handled by event-driven infrastructure.
- Data Quality: Incomplete or inconsistent data can degrade model performance significantly. Meroxa’s transformation and monitoring features help filter noise, validate records, and maintain data hygiene.
- Scalability and Flexibility: As data scales, so should the underlying pipeline. Meroxa provides auto-scaling and configuration management to handle spikes in incoming streams.
- Real-Time Processing: Low-latency ingestion means that ML models can be retrained or updated quickly when new data indicates a shift in trends.
By offloading the complexities of real-time ingestion and transformations to Meroxa, data teams can concentrate on building better ML models and orchestrating the MLOps pipeline, rather than wrestling with data pipeline intricacies.
Why Databricks for Model Development and Deployment?
Databricks offers a unified data analytics platform built on top of Apache Spark, providing a collaborative environment for data engineering, data science, and machine learning teams. Key components of Databricks relevant to MLOps include:
- Delta Lake: A robust data storage layer that allows ACID transactions, schema enforcement, and time travel. This is crucial for maintaining consistency and auditing changes in training data.
- Databricks MLflow: A framework for experiment tracking, model versioning, and deployment. MLflow also integrates with popular ML libraries (e.g., TensorFlow, PyTorch, scikit-learn).
- Notebook Collaboration: Interactive notebooks allow data scientists and engineers to develop and test models collaboratively in a scalable environment.
- Job Scheduling and Workflows: Automate the training, tuning, validation, and deployment steps, integrating them with external systems via REST APIs.
Seamless Integration with Meroxa
In a continuous MLOps pipeline, Databricks acts as the brains for model training and deployment, while Meroxa handles the data flow. The integration can be configured so that:
- Live Data Flow from Meroxa to Databricks: Meroxa streams data into a Delta Lake table or an ingestion endpoint that Databricks can consume.
- Automated Model Triggering: As new data arrives, Databricks jobs can be triggered to retrain models or update inference pipelines.
- Feedback Loop to Meroxa: Databricks can push real-time predictions or insights back to a streaming pipeline, enabling downstream systems to act on them immediately.
By combining Meroxa’s real-time data handling with Databricks’ advanced analytics and ML capabilities, organizations can bridge the gap between raw data ingestion and production-grade model deployment.
Continuous Model Training and Deployment
A hallmark of MLOps is the ability to continually retrain and redeploy models when performance metrics degrade or when data distribution shifts. Databricks facilitates this by:
- Experiment Tracking with MLflow: Each training run is logged, along with hyperparameters, metrics, and metadata. If a newer model outperforms the old one, it can be automatically promoted to production.
- Model Registry: Databricks’ model registry helps keep track of multiple versions of models, ensuring that only validated versions reach production environments.
- Automated Testing: You can automate unit tests for data transformations, model performance tests, and integration tests to ensure that new models maintain or improve performance.
Building Continuous MLOps Pipelines
The diagram above illustrates how data flows from various sources into Meroxa, then into Databricks. Once models are trained, validated, and deployed, the results feed back into the pipeline, creating a continuous loop of data and insight.
- Data Sources: Real-time data from transactions, sensors, or logs.
- Meroxa Ingestion and Transformation: Meroxa connectors capture and stream data. Transformations (e.g., data cleaning, enrichment) happen in flight.
- Data Landing in Delta Lake: Transformed streams land in a Delta Lake table within Databricks for structured storage and ACID compliance.
- Model Training Pipeline: A Databricks job automatically triggers to retrain models based on new data availability or on a specific schedule (e.g., every hour or whenever X new records arrive).
- Validation and Testing: The newly trained model is validated against test sets. Metrics are recorded in MLflow.
- Production Model Deployment: If the new model passes validation thresholds, MLflow or the Databricks model registry updates the model version in the production environment.
- Real-Time Inference: The production model can be hosted on Databricks Serving, a REST endpoint, or a streaming pipeline that connects back into Meroxa.
- Continuous Feedback Loop: Predictions and performance metrics are fed back into the pipeline, allowing for ongoing monitoring and retraining.
Real-Time Data & Model Workflow
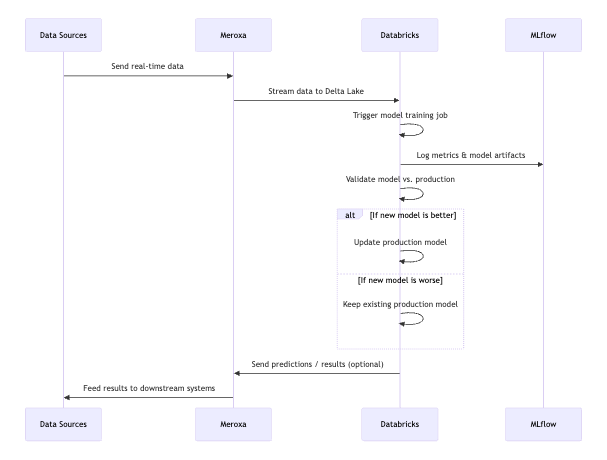
In the sequence diagram above, Meroxa (MX) streams data to Databricks (DB), which trains and validates an ML model. Metrics are tracked in MLflow (MF), and after validation, the new model may replace the existing production model. The pipeline completes when predictions and performance data flow back into Meroxa for real-time consumption by downstream apps.
Set Up Meroxa Pipelines
- Configure Connectors: Select source connectors (e.g., a payment gateway, Kafka topic, or user activity logs) and a destination connector for Databricks (or a compatible endpoint).
- Apply Transformations: Define real-time transformations such as filtering out invalid records, anonymizing sensitive data, or joining with metadata tables.
- Monitor Pipeline Health: Use Meroxa's dashboard or CLI tools to track throughput, latency, and error rates.
Prepare Databricks Workspace
- Provision a Cluster: Configure a Databricks cluster with the necessary compute and libraries (Spark MLlib, TensorFlow, PyTorch, etc.)
- Create Delta Tables: Set up a Delta Lake table schema to accommodate the transformed data from Meroxa.
- Integrate MLflow: Ensure MLflow is enabled for tracking experiments, models, and parameters.
Design the Training Pipeline
- Notebook Development: In a Databricks notebook, define your feature extraction steps, model architecture, and training procedures.
- Automated Trigger: Use Databricks Jobs to schedule or event-trigger your notebook whenever new data arrives in the Delta table.
- MLflow Logging: Log relevant metrics (accuracy, precision, recall, etc.) to MLflow for each run. Store the trained model artifacts in MLflow's model registry.
Validate and Deploy Models
- Validation Step: Compare the new model's performance metrics against the currently deployed model.
- Release to Production: If performance improvements meet your threshold, automatically deploy the new model to a production endpoint or scheduled job for real-time inference.
- Rollback Mechanism: In case of unexpected performance issues, quickly revert to the previously successful model version stored in MLflow.
Advantages of Continuous Feedback
- Up-to-Date Models: Frequent retraining with the latest data minimizes model drift and maintains higher predictive accuracy.
- Faster Iteration: Real-time feedback loops enable rapid testing of new hypotheses and model architectures, accelerating R&D.
- Automated Monitoring: As predictions are generated, key metrics (e.g., accuracy, latency, resource usage) are monitored and fed back into the pipeline, creating a continuous improvement loop.
Minimizing Integration Complexity
While many solutions claim to support real-time pipelines, integration complexity often stalls adoption. Meroxa, by contrast, is purpose-built to reduce friction at every step:
- Unified Configuration: Instead of juggling various scripts or YAML files across multiple services, Meroxa provides a centralized interface to configure your data flows. This simplifies the pipeline creation process for data engineers.
- Pre-Built Connectors: With a library of managed connectors, you can plug into popular data sources (SQL/NoSQL databases, event buses, SaaS applications) without writing custom code. This shortens the timeline from proof-of-concept to production.
- Seamless Databricks Integration: Meroxa automatically routes data to Delta Lake tables or endpoints accessible by Databricks. Configure your pipeline once, and new data flows in near real time—no complicated bridging scripts needed.
- Self-Service & Automation: Meroxa's low-code/no-code philosophy lets non-specialists set up and modify streaming pipelines. This frees your core engineering team to focus on higher-level tasks like optimizing models.
Optimizing Total Cost of Ownership (TCO)
Beyond easy integration, cost management is a major factor in evaluating any new platform. Meroxa offers significant TCO advantages by:
- Reducing Data Engineering Overhead
- Eliminate Custom Code: Every hour spent coding one-off connectors or troubleshooting ingestion scripts adds cost. Meroxa's managed connectors reduce the burden on developers and accelerate time-to-market.
- Streamlined Maintenance: Automated pipeline monitoring, schema change handling, and alerting minimize ongoing maintenance. Fewer break-fix cycles mean lower operational costs.
- Optimizing Compute Resources
- Real-Time Stream Processing: Meroxa processes data continuously, avoiding batch processing spikes. Resources scale with data flow instead of running at full capacity on fixed schedules.
- Targeted Transformations: Pre-processing data in flight ensures only relevant data reaches Databricks or Delta Lake. This upstream filtering reduces storage and CPU usage, especially for large datasets.
- Auto-Scaling & Pay-as-You-Go: Meroxa automatically scales pipeline resources as data volumes change. This ensures you pay only for needed capacity, avoiding costly over-provisioning.
- Enhancing Model Efficiency
- Higher-Quality Input: Cleaner, more consistent data leads to more effective training runs. Models converge faster and need fewer re-runs, saving Databricks compute costs.
- Faster Iterations: Quick model updates catch performance issues early, preventing wasted compute on suboptimal versions.
In short, Meroxa's approach to data ingestion and stream processing accelerates ML project delivery while controlling compute and operational expenses. When combined with Databricks' scalable environment, you get a cost-effective, robust platform for real-time MLOps at enterprise scale.
Real-World Applications & Benefits
Real-time data ingestion and continuous MLOps aren’t just buzzwords; they solve pressing, bottom-line challenges across various industries. Here’s how it looks in practice, with Meroxa and Databricks delivering rapid, adaptive machine learning.
E-Commerce
Challenge
E-commerce companies often rely on outdated or batch-driven recommendations, resulting in stale product suggestions that don’t reflect a user’s most recent clicks and purchase behavior. The result? Low engagement and missed upsell opportunities.
Solution
With Meroxa handling real-time clickstream ingestion, raw event data (page views, shopping cart activity, searches) continuously streams into Databricks and updates ML models in near real time. As soon as a user clicks on a product, that data is transformed and available for on-the-fly recommendation model retraining or feature updates.
Impact
- Personalized Offers: Visitors immediately see recommendations based on their latest browsing.
- Increased Conversions: By serving fresh, relevant suggestions, conversion rates climb.
- Scalable Growth: Auto-scaling real-time pipelines handle peak traffic during sales events without over-provisioning.
E-Commerce Real-Time Flow
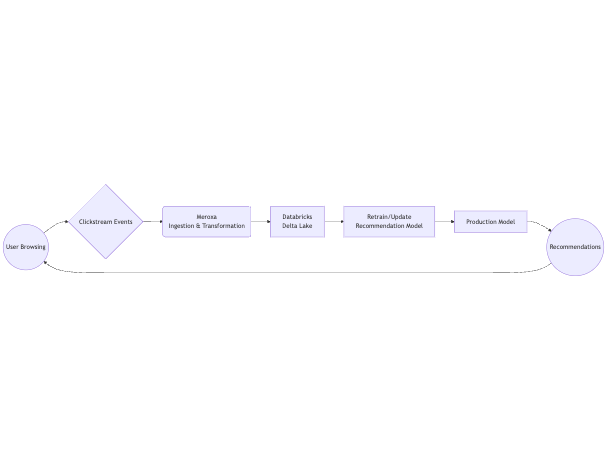
In this flow, Meroxa ingests high-velocity click events, Databricks trains or updates the recommendation model, and the production environment serves personalized suggestions back to the user in seconds.
Finance
Challenge
Banks and payment providers need to detect fraudulent transactions in real time. Traditional batch-based models may flag suspicious activities hours or even days late—leading to financial losses and reputational damage.
Solution
By streaming live transaction records into Meroxa from point-of-sale systems and online payment gateways, data is instantly enriched (e.g., geolocation, user profile) and passed into Databricks for anomaly detection model scoring. If anomalies are detected, the system immediately flags or halts suspicious transactions.
Impact
- Reduced Fraud Losses: Instant detection cuts down on unauthorized activity before it escalates.
- Regulatory Compliance: Updated models help maintain compliance with fast-changing financial rules.
- Improved Customer Trust: Swift fraud alerts demonstrate robust security measures, boosting brand reputation.
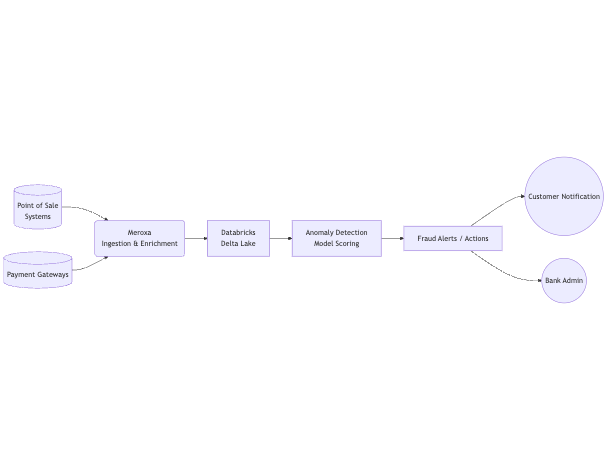
Finance Real-Time Fraud Detection Flow
Meroxa collects transactions from multiple sources (POS, online gateways), enriches them, and streams them into Databricks for real-time anomaly detection. Suspicious activities trigger alerts to both internal teams and potentially to the customers themselves.
Healthcare
Challenge
Healthcare providers struggle to monitor critical patient data—like heart rate or blood pressure—across thousands of IoT devices, creating a data deluge that’s hard to analyze quickly for early warning signs of complications.
Solution
Meroxa ingests continuous sensor readings from wearables or in-facility devices, applying transformations for noise reduction and anonymization. Databricks then applies advanced ML models (e.g., anomaly detection) to flag unusual trends in real time. Alerts are pushed back to clinicians or care teams almost instantly.
Impact
- Proactive Patient Care: Immediate alerts allow medical staff to intervene before minor symptoms become major crises.
- Scalable Management: Cloud-based streaming and MLOps can handle thousands (or millions) of devices without bottlenecks.
- Enhanced Research: Rich real-time data informs predictive studies, improving overall treatment protocols.
Healthcare Real-Time Monitoring Flow
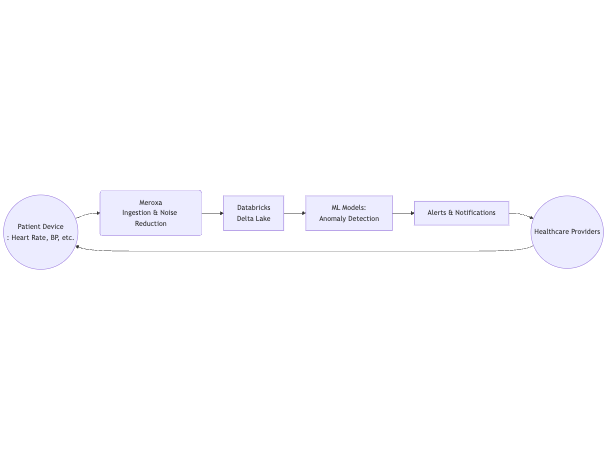
Here, Meroxa handles secure, high-volume ingestion from IoT health devices. Databricks processes and flags critical anomalies so caregivers can respond proactively.
Manufacturing & IoT
Challenge
Factories rely on heavy machinery that can suddenly fail, causing unplanned downtime, safety issues, and lost revenue. Traditional maintenance schedules (weekly or monthly checks) don’t catch emerging problems in real time.
Solution
By streaming sensor data (temperatures, vibration readings, pressure gauges) through Meroxa, anomalies in the data are immediately spotted. Databricks models—trained on historical fault patterns—predict potential failures before they happen, triggering maintenance orders or system shutdowns to prevent accidents.
Impact
- Reduced Downtime: Proactive interventions ensure machines stay operational.
- Cost Savings: Avoiding catastrophic failures saves on repair bills and production delays.
- Operational Safety: Real-time alerts protect workers and assets by halting malfunctioning equipment.
Manufacturing & IoT Predictive Maintenance Flow
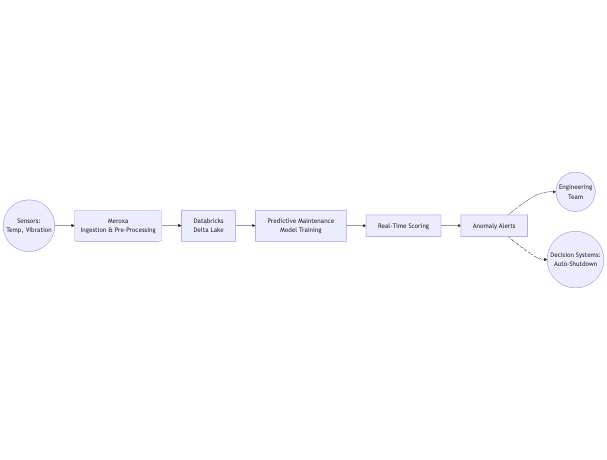
Sensor data is continuously ingested by Meroxa, then used within Databricks to score for potential failures. Alerts can either notify human operators or automatically shut down risky equipment to avoid accidents.
Why This Matters
Across industries, these use cases demonstrate the clear competitive advantage of continuous MLOps:
- Live Data ⇒ Timely, relevant predictions
- Automated Model Updates ⇒ Adaptive to changing conditions
- Real-Time Insights ⇒ Proactive, data-driven decisions
From e-commerce startups to global banks, Meroxa + Databricks transforms raw data into actionable intelligence—protecting revenue, boosting customer satisfaction, and driving innovation.
Conclusion
A continuous MLOps pipeline with real-time feedback loops has become essential for staying competitive in today's data-driven markets. By pairing Meroxa's real-time data ingestion and stream processing capabilities with Databricks' powerful model development, deployment, and monitoring tools, you can build an end-to-end system that evolves seamlessly with new data.
Key Takeaways:
- MLOps Is the Future of ML: Traditional ad-hoc machine learning approaches can't keep pace with today's evolving data and business needs. MLOps delivers the repeatability, scalability, and maintainability modern organizations require.
- Real-Time Feedback Loops Drive Better Outcomes: By incorporating streaming data into your pipeline, your models learn faster and maintain higher accuracy over time.
- Meroxa and Databricks Form a Powerful Tandem: Build intelligent solutions without reinventing data pipelines and machine learning infrastructure from the ground up.
- Start Small, Scale Fast: Begin your continuous MLOps pipeline with a single use case, then expand the framework to additional data sources and models as you grow.
- Minimal Friction & Strong ROI: Meroxa's seamless integration and cost-optimizing features make adopting real-time pipelines easier, delivering faster time-to-value and lower TCO.
Ready to see how Meroxa and Databricks can transform your ML initiatives? Connect with our team or start a proof of concept (POC). With the right tools and architecture, you'll be delivering scalable, insightful, and responsive machine learning solutions in no time.
Interested in learning more?




