
Snowflake is a company that offers cloud-based storage options. Customers don't have to set up or maintain servers because the whole data storage service is entirely managed. While it has several benefits for consumers, including simplicity, speed, and the ability to easily share data, many criticize it’s high price due to the high volume of queries users need to make and the amount of data they need to store on Snowflake.
Some companies have tried to keep their Snowflake costs down by limiting business use or making the data warehouse developers do more work to limit the number of events that get sent to Snowflake. These methods aren't always feasible, they're often time-consuming and tedious, and they only offer marginal savings.
With Meroxa, companies can cut their Snowflake storage and compute costs and make their developers much more productive. Meroxa allows you to easily:
- Filter data before it's ingested
- Denormalize data to reduce compute costs
- Reduce operational costs
What is Meroxa?
Meroxa is a Stream Processing Application Platform as a Service (SAPaaS) where developers can run their Meroxa Turbine applications. Turbine is a stream processing application framework for building event-driven stream processing apps that respond to data in real-time and scale using cloud-native best practices. Meroxa handles the underlying streaming infrastructure so that developers can focus on building their applications. Turbine applications start with an upstream resource. Once that upstream resource is connected, Meroxa will take care of streaming the data into the Turbine application so that it can be run. Since Meroxa is a developer-first platform, engineers can ingest, orchestrate, transform, and stream data to and from anywhere using languages they already know, such as Go, JavaScript, Python, or Ruby. Support for Java, and C# is also on the way.
💡 Meroxa has support for many resources to get data from and to. You can see which resources are supported here. If there's a resource not listed you can request it by joining our community or by writing to support@meroxa.com. Meroxa is capable of supporting any data resource as a connector.
How Meroxa reduces Snowflake costs
Filtering data before it's ingested
Before putting data into Snowflake, unnecessary information should be filtered away to save storage and processing costs in addition to reducing the quantity of data. Data is kept in micro-partitions based on the date and time of ingestion as it is imported into Snowflake. More micro-partitions are produced as more data is loaded into Snowflake, which may result in higher storage costs. In just a few lines of code, we can use Meroxa to filter away irrelevant data before loading it into Snowflake.
A simple example in Turbine (Python), where we filter the data based on orderDollarValue would look like this:
import logging
import sys
from turbine.runtime import RecordList
from turbine.runtime import Runtime
def filter(records: RecordList) -> RecordList:
logging.info(f"processing {len(records)} record(s)")
filtered_records = []
for record in records:
try:
payload = record["payload"]
orderDollarValue = payload["orderDollarValue"]
# Keep only records where orderDollarValue > 10000
if orderDollarValue > 10000:
filtered_records.append(record)
except Exception as e:
print("Error occurred while parsing records: " + str(e))
logging.info(f"output: {record}")
return filtered_records
class App:
@staticmethod
async def run(turbine: Runtime):
try:
# Load and Read Tables from any source
source = await turbine.resources("myPostgreSQL") # MySQL, Sql Server, Kafka, Mongo etc
records = await source.records("customer_orders", {})
# Process Data
filtered = await turbine.process(records, filter)
# Write to any Destination
destination_db = await turbine.resources("mySnowflake")
await destination_db.write(filtered, "collection_archive", {}) # Snowflake, S3, Mongo, Redshift etc
except Exception as e:
print(e, file=sys.stderr)Denormalize data to reduce compute costs
Spending less time and money on maintaining Snowflake can help you save money by making it easier to find important information faster. By denormalizing the data with Meroxa before loading it into Snowflake, more information is added that can be used to better understand and analyze the data. The denormalized data may have answers to certain questions or may be better organized and structured in a way that makes it easier to query.
In Turbine (Javascript), a simple example of enriching and denormalize addresses in our records using a third-party API would look like this:
// Import any dependencies just like a regular application
const { googleMapsLookup, generateAddressObject } = require('./googleMapsApi.js')
export class App {
enrich(records) {
records.forEach((record) => {
// Call the Google Maps API and enrich the address on each record
const addressLookupResults = googleMapsLookup(record.get('address'))
const addressMetaData = generateAddressObject(addressLookupResults)
record.set('address_metadata', addressMetaData);
});
return records;
}
async run(turbine) {
// Load and Read Tables from any source
let source = await turbine.resources("myPostgreSQL"); // MySQL, Sql Server, Kafka, Mongo etc
let records = await source.records("customer_shipping");
// Process Data
let enriched = await turbine.process(records, this.enrich);
// Write to any Destination
let destination = await turbine.resources("mySnowflake"); // Snowflake, S3, Mongo, Redshift etc
await destination.write(enriched, "enriched_customer_shipping");
}
}💡 For a more detailed example on using API’s & doing transformations in Turbine you can read our blog post here.
Reduce operational costs
Meroxa allows developers of any level to build data pipelines to ingest, orchestrate, transform, and stream data to and from anywhere using languages they already know. This process typically requires Snowflake subject matter experts and can take months to deliver data projects. Meroxa allows anyone to be a snowflake expert and reduces the number of hours and resources needed to support Snowflake, ultimately delivering data projects faster.
A typical workflow for a data project with Meroxa is cost-effective, enterprise-ready in days, allows for rapid prototypes & conclusions, and offers code reusability:
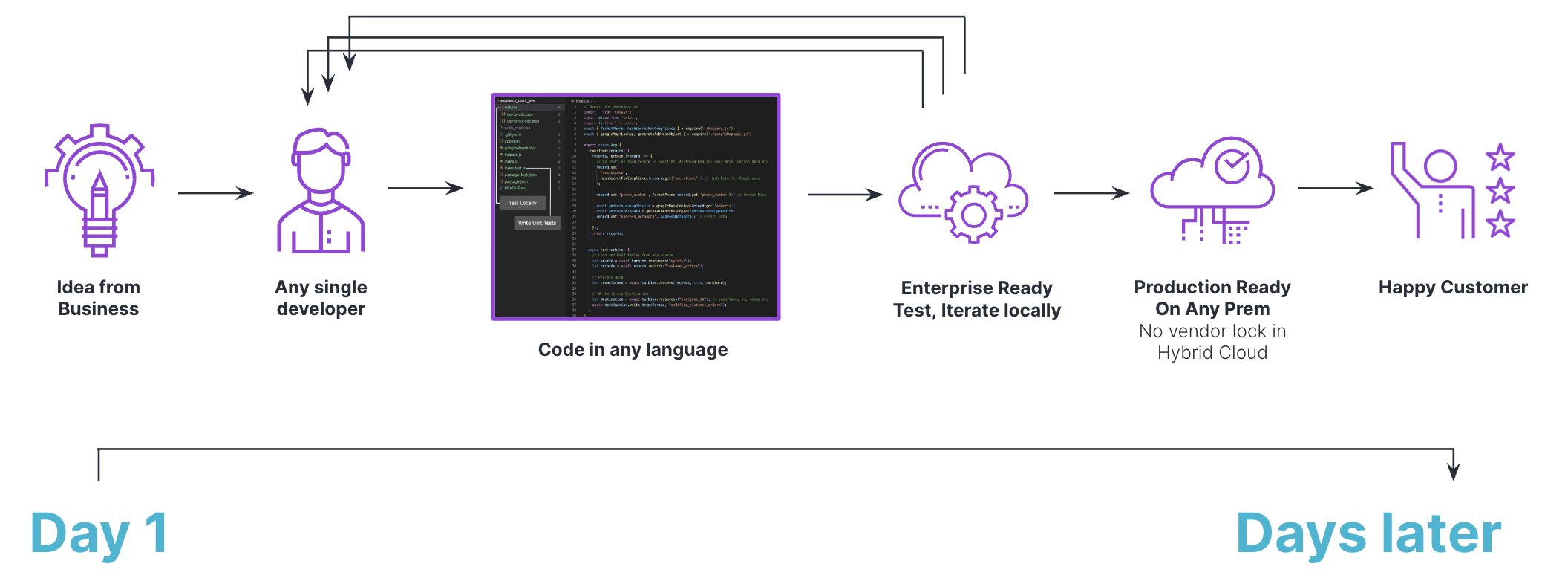
Meroxa Key Benefits
Code First - Developers can build data products in the language of their choice with the ultimate flexibility that code provides. Import packages, and modules to easily build with data.
Open-Source - Built on open-source technology to give enterprises the security and flexibility they need. No vendor lock-in.
Easily manage hundreds of integrations - Our innovative platform automatically creates a shared data stream catalog and embeds it into your workflows so you can search, find, and reuse data streams effortlessly.
Automatically connect, configure, and orchestrate data integrations - Don’t stress over data orchestration: our platform has over a dozen pre-configured integrations for databases, cloud, SaaS apps, and streaming services…and we’re adding more on a regular basis.
Scale dynamically with serverless architecture - Build reusable and scalable components with standardized processes, allowing you to work efficiently while maximizing available resources.
Build, Test, Deploy - it’s that simple. Build your stream processing application using a language of your choice, test with data we sample for you, and deploy your application.
Want to learn more about how Meroxa can help you realize more value in Snowflake? Schedule a demo today.
Happy Coding 🚀




