
In 2014, Jay Kreps wrote a blog post detailing the Kappa Architecture as a way to simplify the existing Hadoop based architecture for processing data. The Kappa Architecture, as seen in the below diagram, leverages a streaming service like Apache Kafka to be the main source of data removing the need to store data into a filesystem like HDFS for batched based processing.
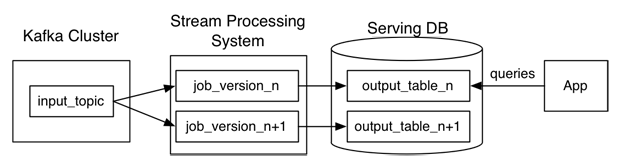
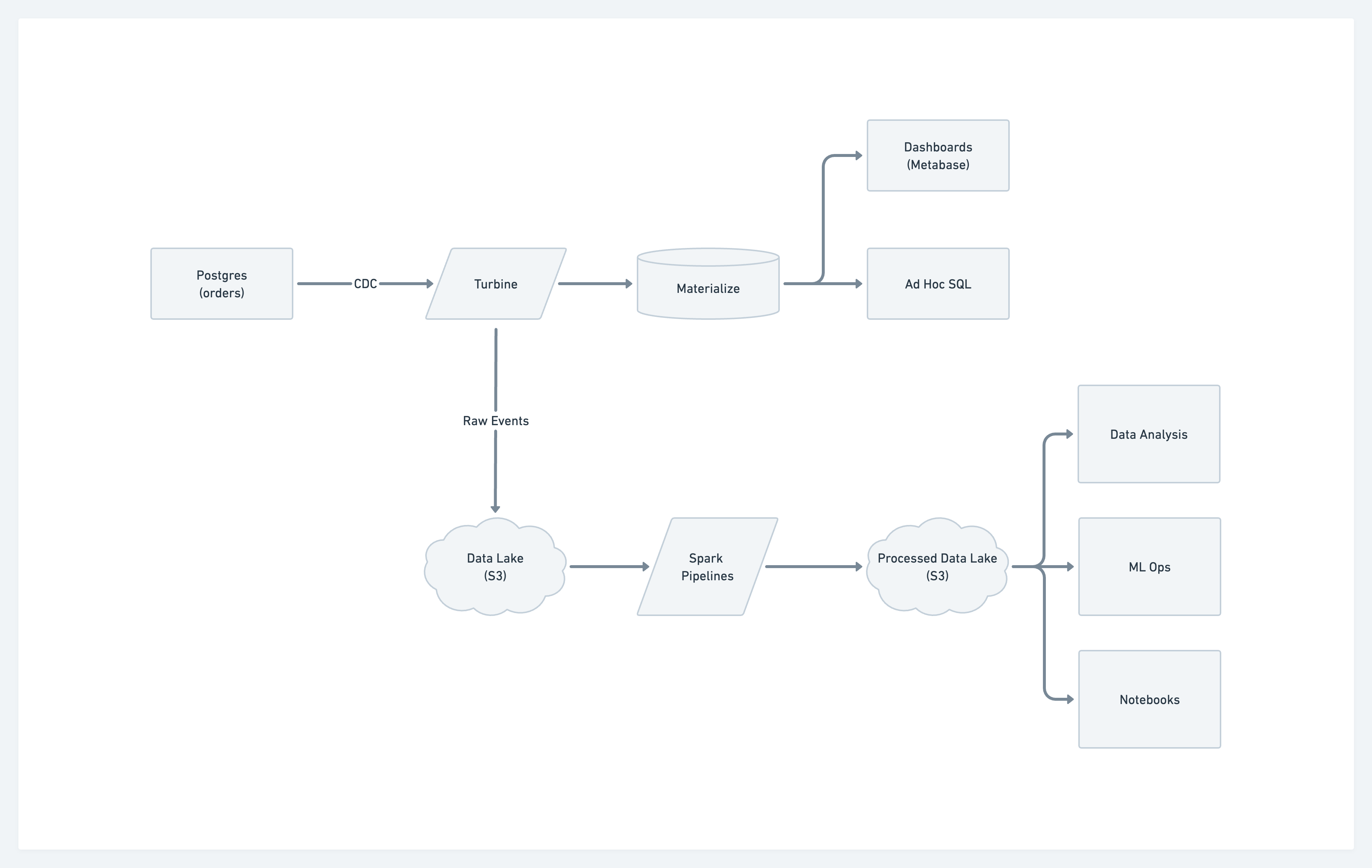
While the benefits of the Kappa Architecture are numerous, operating and maintaining the various infrastructure components for ingestion, streaming, stream processing, and storage is no trivial task. The Meroxa platform and our Turbine SDK make it trivial to deploy and leverage the Kappa Architecture in the below diagram in as few as 20 lines of code.
 Show Me the Code!
Show Me the Code!
We’re going to bring the above diagram to life with Meroxa’s Turbine Go SDK. Turbine currently supports writing data applications in Go, Python, and JavaScript with more languages coming soon.
Turbine Data App Requirements
- Go
- Meroxa account
- Meroxa CLI
- Meroxa supported PostgreSQL DB)
- Amazon S3 Bucket
- Materialize
- Apache Spark (OSS) or Databricks (Paid)
Adding PostgreSQL, S3, and Materialize Resources to the Data Catalog with the Meroxa CLI
The first step in creating a data app is to add the S3 and PostgreSQL resources to the Meroxa catalog. Resources can be added via the dashboard, but we’ll show you how to add them to the catalog via the CLI.
Adding PostgreSQL (docs)
$ meroxa resource create pg_db \\
--type postgres \\
--url "postgres://$PG_USER:$PG_PASS@$PG_URL:$PG_PORT/$PG_DB" \\
--metadata '{"logical_replication":"true"}'If your database supports logical replication, set the metadata configuration value to true.
Adding S3 (docs)
$ meroxa resource create dl \\
--type s3 \\
--url "s3://$AWS_ACCESS_KEY:$AWS_ACCESS_SECRET@$AWS_REGION/$AWS_S3_BUCKET"Adding Materialize (docs)
Materialize is wire-compatible with PostgreSQL, which means we can use the standard connection string format.
$ meroxa resource create mz_db \\
--type materialize \\
--url "postgres://$PG_USER@$PG_URL:$PG_PORT/$PG_DB"Initializing a Turbine Go Data App
$ meroxa apps init pg_kappa --lang go When initializing the Turbine app, you’ll see we include many comments and boilerplate to help you get up and going. We removed most of this for this example, but take a look around and even execute meroxa apps run to see the output of our sample app.
Creating the Kappa Architecture with Turbine
Inside of the main App we can ingest the data from our PostgreSQL DB(pg_db) and orchestrate in real-time to our destinations Materialize(mz_db) and AWS S3(dl) as seen in the code block below. We’ll take data from the orders table using change data capture (CDC). Every time there is a change in the PostgreSQL source, our Turbine data app will keep our destinations in sync.
func (a App) Run(v turbine.Turbine) error {
source, err := v.Resources("pg_db") // create connection to Postgres db
if err != nil {
return err
}
rr, err := source.Records("orders", nil) // ingest data from orders table
if err != nil {
return err
}
materialize, err := v.Resources("mz_db") // create connection to Materialize db
if err != nil {
return err
}
datalake, err := v.Resources("dl") // create connection to AWS S3 data lake
if err != nil {
return err
}
err = materialize.Write(rr, "orders") // stream orders data to Materialize
if err != nil {
return err
}
err = datalake.Write(rr, "dl_raw") // stream orders data to AWS S3
if err != nil {
return err
}
return nil
}Now that the data is flowing, you can use a BI tool like Metabase to query the data in Materialize for real-time data analysis or to build dashboards.
Processing Data from S3 with Spark
As data flows into your data lake in real-time, you can process and analyze it utilizing Spark. In S3, Turbine stores the data from PostgreSQL as one line, gzipped JSON as seen below.
 Postgres CDC data in S3
Postgres CDC data in S3
The schema of the gzipped record looks like the following:
{
"schema": {
"name": "turbine-demo",
"optional": false,
"type": "struct",
"fields": [
{
"field": "id",
"optional": false,
"type": "int32"
},
{
"field": "email",
"optional": true,
"type": "string"
}
]
},
"payload": {
"id": 1,
"email": "devaris@devaris.com"
}
}To read that data in Spark and write out to another S3 bucket, it’s pretty trivial to do with [PySpark](https://spark.apache.org/docs/latest/api/python/#:~:text=PySpark is an interface for,data in a distributed environment) as seen below.
import pyspark
# Set up a Spark Session and your S3 config
from pyspark import SparkConf
from pyspark.sql import SparkSession
conf = SparkConf()
conf.set('spark.jars.packages', 'org.apache.hadoop:hadoop-aws:3.2.0')
conf.set('spark.hadoop.fs.s3a.aws.credentials.provider', 'org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider')
conf.set('spark.hadoop.fs.s3a.access.key', )
conf.set('spark.hadoop.fs.s3a.secret.key', )
conf.set('spark.hadoop.fs.s3a.session.token', )
spark = SparkSession.builder.config(conf=conf).getOrCreate()
# Read data from the CSV
df = spark.read.json("s3a://dl_raw/file.jl.gz")
# Do some processing on the dataframe then write to a new bucket in CSV format
df.write.format("csv").option("header","true").save("s3a://dl_processed_csv")Deploying
Now that the application is complete, we can deploy the solution in a single command. The Meroxa Platform sets up all the connections and orchestrates the data in real-time so you don’t have to worry about the operational complexity.
$ meroxa apps deploy pg_kappa Conclusion
The Meroxa platform and our Turbine SDK take the complexity out of operating and leveraging the Kappa Architecture. With less than 20 lines of code, we were able to deploy a solution that enables real-time analytics with Materialize and leveraged Spark’s stream processing for ML, Data Science, etc… in a separate workflow.
We can’t wait to see what you build 🚀
Get started by requesting a free demo of Meroxa. Your app could also be featured in our Data App Spotlight series. If you’d like to see more data app examples, please feel free to make your request in our Discord channel.

- Share Real-Time Analytics Using the Kappa Architecture in ~20 Lines of Code with Turbine, Materialize, Spark, & S3 on Facebook

- Share Real-Time Analytics Using the Kappa Architecture in ~20 Lines of Code with Turbine, Materialize, Spark, & S3 on Twitter

- Share Real-Time Analytics Using the Kappa Architecture in ~20 Lines of Code with Turbine, Materialize, Spark, & S3 on LinkedIn

