
Financial institutions face an ever-present challenge in detecting fraudulent transactions quickly. Today, we’ll showcase how Conduit and Feast can seamlessly work with Databricks to build a scalable, real-time fraud detection system.
- Conduit from Meroxa: A high-performance platform for data ingestion and transformation, complete with built-in processors.
- Feast: An open-source feature store for managing features in both offline (batch) and online (low-latency) contexts.
- Databricks: For large-scale data processing, model training, and real-time serving (via MLflow Model Serving or custom endpoints).
Why Conduit?
Conduit offers a lightweight yet powerful way to stream and transform your data with minimal overhead. Key benefits:
- Declarative Pipelines: Define sources, sinks, and transformations via a YAML or JSON config.
- Built-in Processors: Modify, enrich, or filter records in flight (e.g., masking sensitive PII).
- High Throughput: Designed for real-time data pipelines at scale.
Below is a diagram illustrating how Conduit and Feast integrate with Databricks for fraud detection:
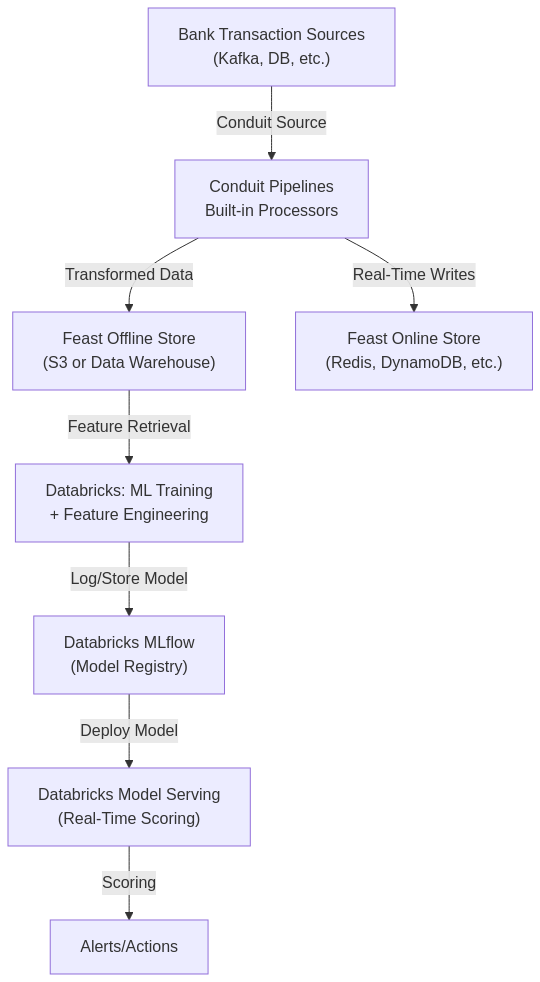
- Conduit ingests streaming data from transaction sources (e.g., Kafka, databases).
- Built-in processors within Conduit enrich/cleanse data.
- Conduit writes offline features to the Feast Offline Store (could be S3 or a relational warehouse).
- Conduit can simultaneously push the latest features to the Feast Online Store (like Redis) for low-latency inference.
- Databricks reads from the Feast offline store, trains the fraud model, and registers it in MLflow.
- Databricks Model Serving (or a custom endpoint) hosts the model for real-time scoring.
- Requests for fraud scoring read any updated features from Feast’s online store.
Step 1: Conduit Data Pipeline
1.1 Conduit Configuration
Assume we have a Kafka topic (bank_transactions) containing real-time financial transactions and a PostgreSQL database with watchlist data. Below is an example conduit.config.yaml snippet that ingests from Kafka and writes to S3 (for offline store) and Redis (for online store), using Feast as the consumer reference.
yaml
CopyEdit
version: "v1"
sources:
kafkaTransactions:
type: kafka
settings:
brokers: "broker1:9092,broker2:9092"
topics: ["bank_transactions"]
consumerGroupID: "fraud-cg"
processors:
- name: parseJSON
type: processor.json
settings:
action: "unmarshal"
field: "value"
- name: addWatchlistFlag
type: processor.lookup
settings:
# Hypothetical config that references a PostgreSQL watchlist
dataStore: "postgresql://user:pass@db.example.com:5432/bankdb"
sourceField: "value.account_id"
targetField: "value.watchlist_flag"
query: "SELECT account_id, true as watchlist_flag FROM watchlist WHERE account_id = $1"
sinks:
# Sink to offline store (S3, which Feast can read from)
s3Offline:
type: s3
settings:
bucket: "feast-offline-store"
region: "us-east-1"
# Additional config (credentials, etc.)
processors: []
# Sink to online store (e.g., Redis for Feast)
redisOnline:
type: redis
settings:
address: "redis-host:6379"
processors: []
pipelines:
myFraudPipeline:
sources: ["kafkaTransactions"]
processors: ["parseJSON", "addWatchlistFlag"]
sinks: ["s3Offline", "redisOnline"]
Explanation:
- parseJSON: A built-in processor that unmarshals the JSON in the Kafka “value” field into a structured object.
- addWatchlistFlag: Another built-in processor that queries your PostgreSQL watchlist table to see if
account_idis flagged. The result is appended asvalue.watchlist_flag = true/false. - The pipeline then writes this enriched stream to two sinks:
- s3Offline: So that Feast or Databricks can consume it in batch.
- redisOnline: For near real-time lookups (Feast online store).
1.2 Running Conduit
conduit run --config conduit.config.yamlConduit starts streaming transactions from Kafka, applying processors, and writing to both S3 and Redis. Now we have data continuously updating:
- Offline store: Historical features in S3 (or columns/partitions for transaction data).
- Online store: Real-time features in Redis keyed by
account_id
Step 2: Managing Features with Feast
2.1 Feast Repository Setup
In your feature_store.yaml, configure S3 as the offline store and Redis as the online store:
project: "fraud_project"
registry: "s3://my-bucket/feast/registry.db"
provider: "local"
offline_store:
type: file
path: "s3://feast-offline-store" # where Conduit is writing
online_store:
type: redis
connection_string: "redis-host:6379"
2.2 Define Fraud Feature Views
Example: “transaction_features.py”
from feast import Entity, FeatureView, Field
from feast.types import Float32, Int32, Bool
account = Entity(name="account_id", join_keys=["account_id"])
transaction_feature_view = FeatureView(
name="transaction_features",
entities=[account],
ttl=None,
schema=[
Field(name="amount", dtype=Float32),
Field(name="watchlist_flag", dtype=Bool),
Field(name="transaction_count_last_10m", dtype=Int32),
# ...
],
online=True,
offline=True,
)
When new transactions arrive (through Conduit), they land in S3 and Redis in near real-time. With Feast, you can:
- Materialize historical data from S3 for offline training.
- Keep the same features fresh in Redis for online inference.
Step 3: Training a Fraud Detection Model in Databricks
3.1 Pull Historical Features
import feast
import pandas as pd
from feast import FeatureStore
fs = FeatureStore(repo_path="path/to/feature_repo")
# Example: create an entity DataFrame with known fraud labels for training
entity_df = pd.DataFrame({
"account_id": [...],
"event_timestamp": [...], # timestamps for each transaction
"fraud_label": [...]
})
training_df = fs.get_historical_features(
entity_df=entity_df,
feature_refs=["transaction_features:amount",
"transaction_features:watchlist_flag",
"transaction_features:transaction_count_last_10m"]
).to_df()
# training_df now includes the needed columns + your label3.2 Train a Model (e.g., LightGBM)
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
pdf = training_df.dropna() # remove partial data
X = pdf.drop(columns=["fraud_label", "event_timestamp", "account_id"])
y = pdf["fraud_label"]
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
dtrain = lgb.Dataset(X_train, label=y_train)
dtest = lgb.Dataset(X_test, label=y_test, reference=dtrain)
params = {
"objective": "binary",
"metric": "auc",
"is_unbalance": True
}
model = lgb.train(params, dtrain, num_boost_round=100, valid_sets=[dtest], early_stopping_rounds=10)
y_pred = model.predict(X_test)
auc = roc_auc_score(y_test, y_pred)
print(f"Test AUC: {auc:.4f}")3.3 Register in MLflow
import mlflow
import mlflow.lightgbm
mlflow.set_experiment("/Users/your.name@company.com/fraud_experiment")
with mlflow.start_run():
mlflow.lightgbm.log_model(model, artifact_path="model", registered_model_name="FraudDetectionModel")
mlflow.log_metric("auc", auc)
run_id = mlflow.active_run().info.run_id
print(f"Model logged in run: {run_id}")Step 4: Real-Time Fraud Scoring
- Databricks Model Serving (or a custom microservice) hosts the trained model.
- When a new transaction arrives, Conduit has already fed the relevant data to Feast’s online store.
- The serving endpoint:
- Looks up the latest features for
account_idfrom the Feast online store (Redis). - Passes those features to the LightGBM model.
- Returns a fraud probability in real time.
- Looks up the latest features for
- If the fraud probability is above a threshold, an alert or blocking action is triggered.
Conclusion
Conduit seamlessly integrates with Feast and Databricks to enable real-time fraud detection:
- Conduit handles high-throughput, low-latency data ingestion and transformations using built-in processors.
- Feast manages consistent offline and online feature stores (S3 + Redis).
- Databricks powers the ML pipeline (training, model registry, real-time serving).
With this setup, banks and financial institutions can quickly detect and respond to fraudulent transactions, leveraging a robust, scalable data infrastructure.
Ready to learn more?
- Dive into the Conduit documentation for more detailed pipeline configs and processor usage.
- Explore the Feast docs for advanced feature store topics.
- Check out Databricks MLflow docs for model tracking and deployment.
Stay tuned for more guides on building next-generation data pipelines and ML workflows with Conduit and Feast—accelerating your fraud detection, analytics, and beyond. Follow us on Twitter, LinkedIn, and YouTube for more insights and updates!
Happy streaming and safe banking!




