Nobody wants to look at a dashboard or make decisions with yesterday’s data. We live in a world where real-time information is a first-class expectation for our users and is critical to make the best decisions inside an organization.
Change Data Capture (CDC) is an efficient and scalable model that simplifies the implementation of real-time systems.
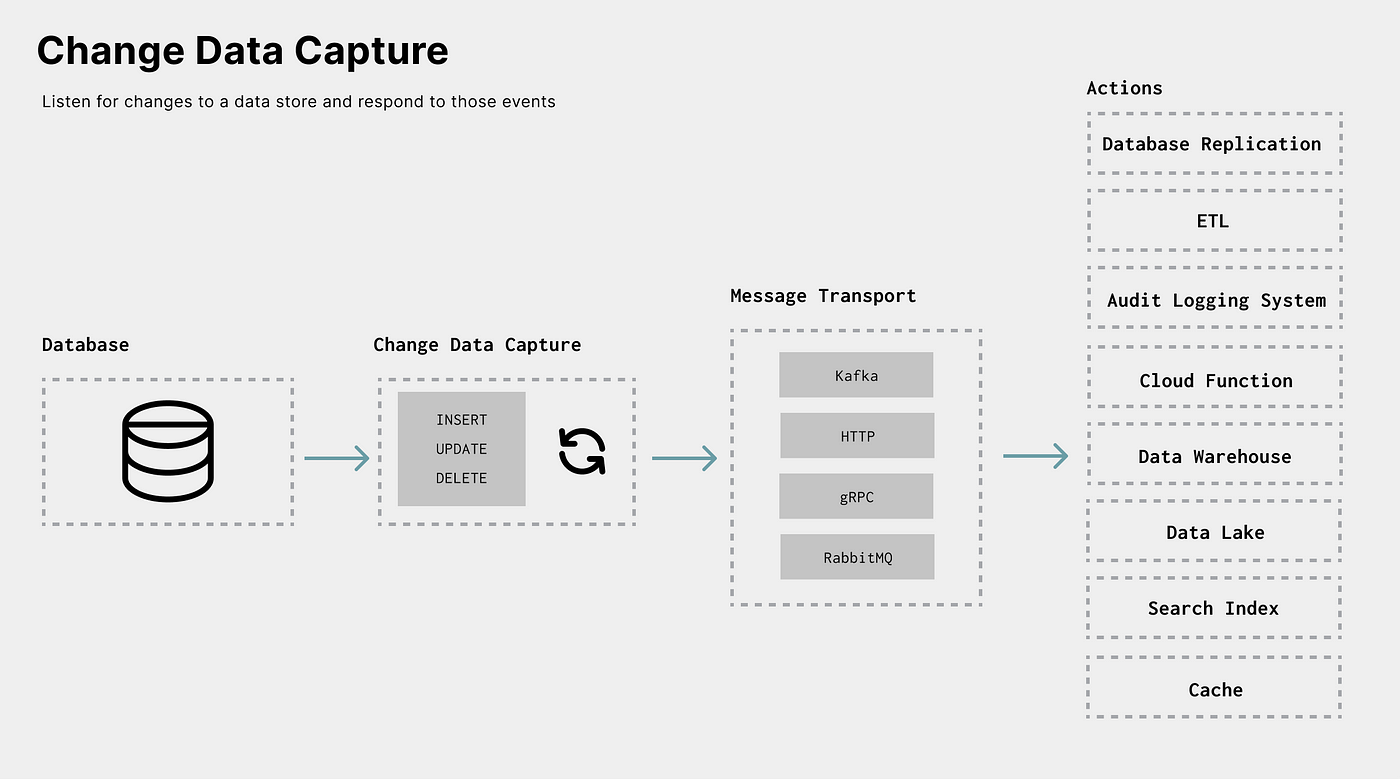
Change Data Capture Diagram
Industry-leading companies likeShopify,Capital One,Netflix,Airbnb, andZendesk, have all published technical articles demonstrating how they have implemented Change Data Capture (CDC) into their data architectures to:
- Expose data from a centralized system to event-driven microservices.
- Build applications that respond to data events in real-time.
- Maintain data quality and freshness within data warehouses and other downstream consumers of data.
In this multi-part series on Change Data Capture, we are going to dive into:
- What is Change Data Capture, and how are CDC systems implemented?
- What are the ideal CDC use cases, and how to get started with CDC?
Let’s begin.
What is Change Data Capture (CDC)?
The idea of “tracking the changes to a system” isn’t new. Engineers have been writing scripts to query and update data in batches since the idea of programming itself came about. Change Data Capture is a formalization of the various methods that determinehow changes are tracked.
At its core, CDC is a process that allows an application to listen for changes to a data store and respond to those events. The process involves a data store (database, data warehouse, etc.) and a system to capture the changes of the data store.
For example, one could:
- CapturePostgreSQL (database) changes and send the change events toKafka usingDebezium (CDC).
- Capture changes fromMySQL (database) and
POSTto an HTTP Endpoint withMeroxa (CDC).
Real-World Example
Let’s look at a real-world example that would benefit from CDC. Here, we have an example of a table in PostgreSQL:
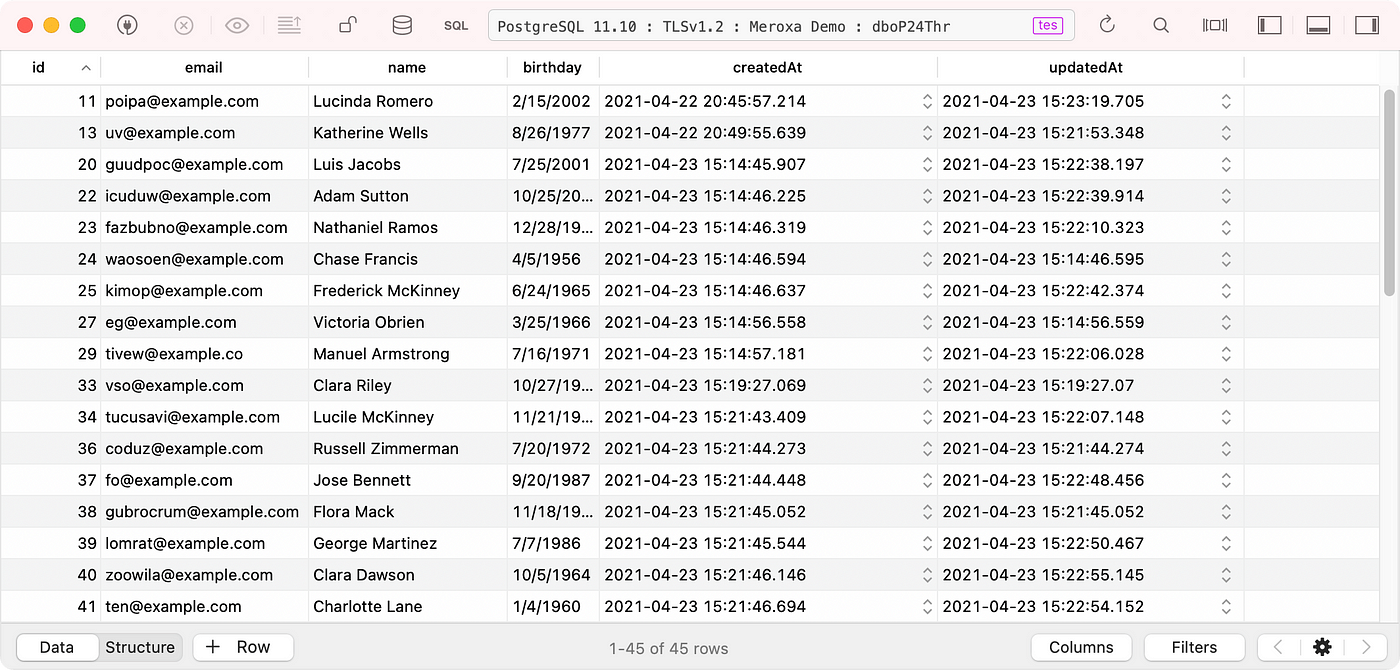
Example User Data
When information in theUser table changes, the business may need to:
- Update the data warehouse, which is the source of truth for business analytics.
- Notify the team of a new user.
- Keep an additional
Usertable in sync with filtered columns for privacy purposes. - Create a real-time dashboard of new user activity.
- Capture change events for audit logging.
- Store every change in a cloud bucket for historical analytics.
- Update an index used for search.
We can build services to perform all of the actions above by acting on a data change event, and if desired, build and manage them independently of each other.
CDC gives us efficiency by acting on events as they occur and scalability by leveraging adecoupled event-driven architecture.
A CDC Event Example
CDC systems will usually emit an event that contains details about the change that occurred. When using a CDC system like Debezium and a new user is created, here is the generated event:

Anatomy of CDC Event
This event describes the schema of the data (schema), the operation that occurred (op), and the data before and afterpayload.
The event’s format, the fidelity of information, and when it is delivered depend on the CDC system’s implementation.
CDC Implementations
Tracking changes to a PostgreSQL database could look very similar or wildly different to tracking changes within MongoDB. It all depends on the environment and the capture method chosen.
The capture method chosen can define:
- what operation(s) (insert, update, delete) can be captured.
- how the event is formatted.
- If the CDC system ispulling the change events or beingpushed to the CDC system.
Let’s look at each of the different methods and discuss some of the pros and cons of each.
Polling
When implementing any database connector, the decision starts with “To poll or not to poll.” Polling is the most conceptually simple CDC method. To implement polling, you need to query the datastore on an interval.
For example, you may run the following query on an interval:
SELECT * from Users;ThisSELECT * query would be considered thebulk ("give me everything") polling method. While this would be great to capture a snapshot of the current state, downstream consumers would require work to figure out exactly what data changed on each interval.
However, polling can get much more granular. For example, it’s possible to poll only for a primary key:
SELECT MAX(id) from Users;A system can track the max value of a primary key (id). When the max value increments, this means that anINSERT operation occurred.
Additionally, if a database has anupdateAt column, a query can look at timestamp changes to captureUPDATE operations.
SELECT * from Users WHERE updated_at > 2021-02-08;Pros and Cons
Easy: Polling is great because it’s simple to implement, deploy, and very effective.
Custom queries are useful: One advantage is that the query used while polling can be customized to fit complex use cases. The query could includeJOINS or transformations performed directly in SQL.
Capturing deletes is hard: With the polling method, it’s much harder to captureDELETE operations. You can't really query a row in a database if it's gone entirely. One solution is to usedatabase triggers to create an "archive" table of deleted records. Then, delete operations become insert operations of a new table that could be polled.
Events are pulled, not pushed: With polling, the event is pulled from the upstream system. For example, when using polling to ingest into a data warehouse, the ingestion would happen when the CDC system decides to poll. In theory, “real-time” can be accomplished with fast enough polling, but this could cause performance overhead to the database.
Performance overhead is a concern: ASELECT * or any complex query doesn't scale very well on massive datasets. One common workaround is by polling a stand-by instance instead of the primary database.
Changes between query times can’t be captured: Another consideration is the data changes between query times. For example, if a system polls every hour and the data changes multiple times within that same hour, you’d only be able to see the change at query times, not any of the intermediate changes.
Database Triggers
Most of the popular databases support triggers of some sort. For example,in PostgreSQL, one can build a trigger that will move a row to a new table when it’s deleted:
CREATE TRIGGER moveDeleted
BEFORE DELETE ON "User"
FOR EACH ROW
EXECUTE PROCEDURE moveDeleted();Because triggers can effectively listen to an operation and perform an action, database triggers can act as a CDC system.
In some cases, these triggers can be very complex and full-blown functions. For example,in MongoDB, Triggers are written in Javascript:
exports = async function (changeEvent) {
// Destructure out fields from the change stream event object
const { updateDescription, fullDocument } = changeEvent;
// Check if the shippingLocation field was updated
const updatedFields = Object.keys(updateDescription.updatedFields);
const isNewLocation = updatedFields.some(field =>
field.match(/shippingLocation/)
);
// If the location changed, text the customer the updated location.
if (isNewLocation) {
// Do something
}
};Pros and Cons
Ease of deployment: Triggers are awesome because they are supported out-the-box for most databases and are easy to implement.
Data Consistency: Any current and new downstream consumer doesn’t have to worry about performing this logic because the logic is contained in the database and not the application — in the case of a microservice architecture.
Application logic in databases could be bad: However, databases should not containtoo much application logic. This could result in behavior being too tightly coupled to the database, and one bad trigger could affect an entire data infrastructure. Triggers should be concise and simple.
Every operation is captured: You can build a trigger for each database operation.
Performance overhead is a concern: Poorly written Triggers can also impact database performance for the same reasons as the polling method. A trigger that contained a complex query wouldn’t scale very well on massive datasets.
Streaming Replication Logs
It’s best to have at least a secondary instance of a database running to ensure proper failover and disaster recovery.
In this model, the standby instances of the database need to stay up-to-date with the primary in real-timeand not lose information. The best way to do this today is for the database to write every change occurring to a log. Then, any standby instances can stream the changes from this log and apply the operations locally. Performing the same operations in real-time is what allows the standby instances to “mirror” the primary.
Here are some references on how this works for some of the most popular databases:
CDC can use the same mechanism to listen to changes. Just like a standby database, an additional system can also process the streaming log as it’s updated:
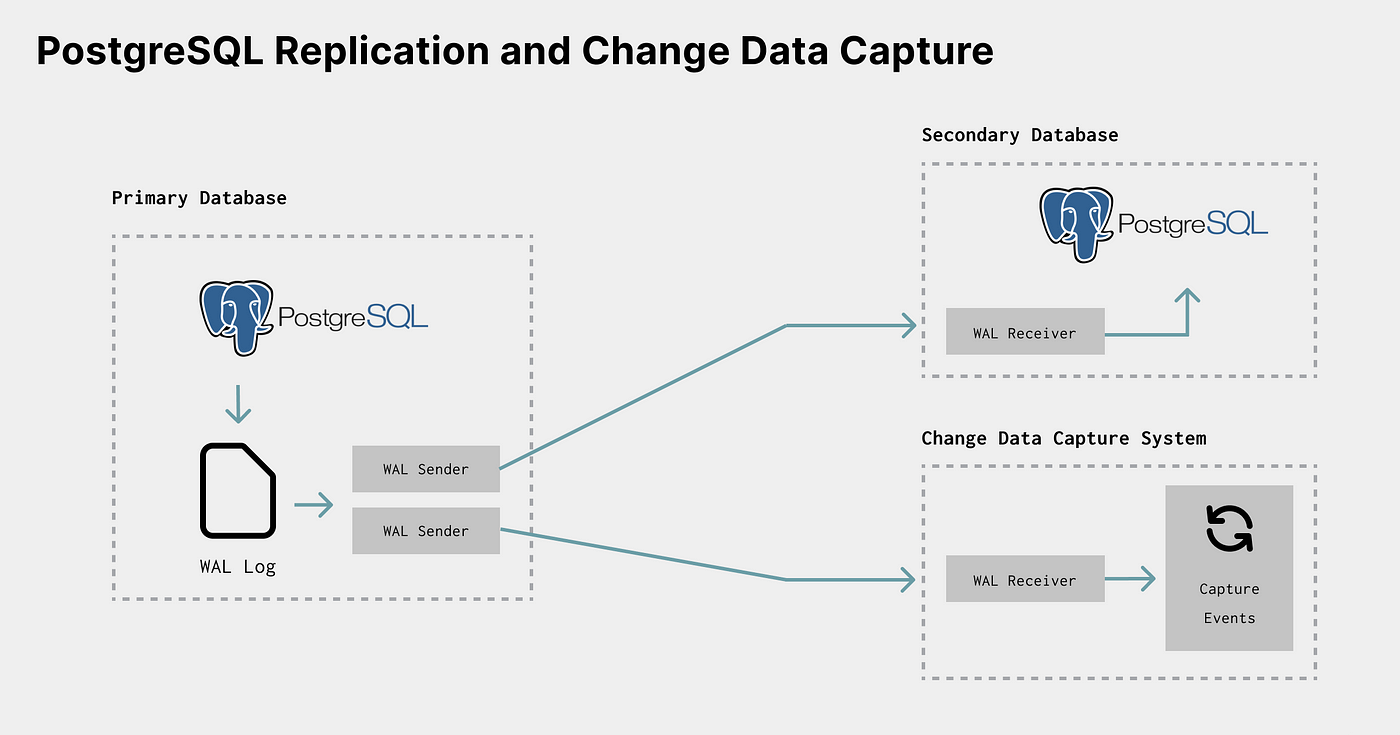
In the PostgreSQL example diagram above, a CDC system can act as an additionalWAL Receiver, process the event, and send to a message transport (HTTP API, Kafka, etc.).
Here is an example of querying changes from PostgreSQL’s WAL using a SQL function provided by the the[test\_decoding](https://www.postgresql.org/docs/10/logicaldecoding-example.html)plugin:
postgres=# SELECT * FROM pg_logical_slot_get_changes('regression_slot', NULL, NULL);
lsn | xid | data
-----------+-------+---------------------------------------------------------
0/BA5A688 | 10298 | BEGIN 10298
0/BA5A6F0 | 10298 | table public.data: INSERT: id[integer]:1 data[text]:'1'
0/BA5A7F8 | 10298 | table public.data: INSERT: id[integer]:2 data[text]:'2'
0/BA5A8A8 | 10298 | COMMIT 10298
(4 rows)In the query response above, it describes the following:
lsn- Log Sequence Number (LSN) - This number describes the current position in the WAL log. It's used by downstream systems when the log has been updated.xid- Transaction ID - Each transaction to PostgreSQL gets a unique ID.data- Data about action and operation that occurred.
The format of these change events will be determined based on theLogical Decoding Output Plugin. For example, thewal2json output plugin allows you to output the changes in JSON, which are easier to parse than thetest_decoding plugin output.
PostgreSQL also provides a mechanism tostream these changes as they occur. As you saw in the event example earlier, Debezium also parses the streaming log in real-time and produces a JSON event.
Pros and Cons
Events are pushed: One huge benefit of streaming logs is that the events are being pushed to the CDC system as changes occur (vs. polling). This pushing model allows for real-time architectures. Using theUser table as an example, the data warehouse ingestion would happen in real-time with a streaming log CDC system.
Efficient and Low Latency: Standby instances use streaming logs for disaster recovery, where efficiency and low latency are top priorities. Streaming replication logs is the most efficient means of capturing changes with the least overhead to the database. This process will look differently from database to database, but the concepts still hold.
Every operation is captured: Every transaction occurring to the data store will be written to the log.
Hard to get a complete snapshot of data: Generally, after a certain amount of time (or size), the streaming logs get purged because they take up space. Being so, the logs may not containevery change that occurred, just the most recent.
Need to be configured: Enabling replication logs may require additional configuration, plugins, or even database restart. Performing these changes with minimal downtown could be cumbersome and requires planning.
What’s Next?
Capturing thechanges of data is like a swiss army knife for any application architecture; it is useful for so many different types of problems. Listening, storing, and acting on the changes of any system — particularly a database — allows you to perform real-time replication data between two data stores, break up a monolithic application into scalable, event-driven microservices, or even power real-time UIs.
Streaming replication logs, polling, and database triggers provide a mechanism to build a CDC system. Each has its own set of pros and cons specific to your application architecture and desired functionality.
In thenext article in this series, we are going to dive into:
- What are the ideal CDC use cases?
- Where can I get started with CDC?
I can’t wait to see what you build 🚀.
Special thanks to@criccomini,@andyhattemer,@misosoup,@devarispbrown, and@neovintage for helping me craft the ideas in this article!



