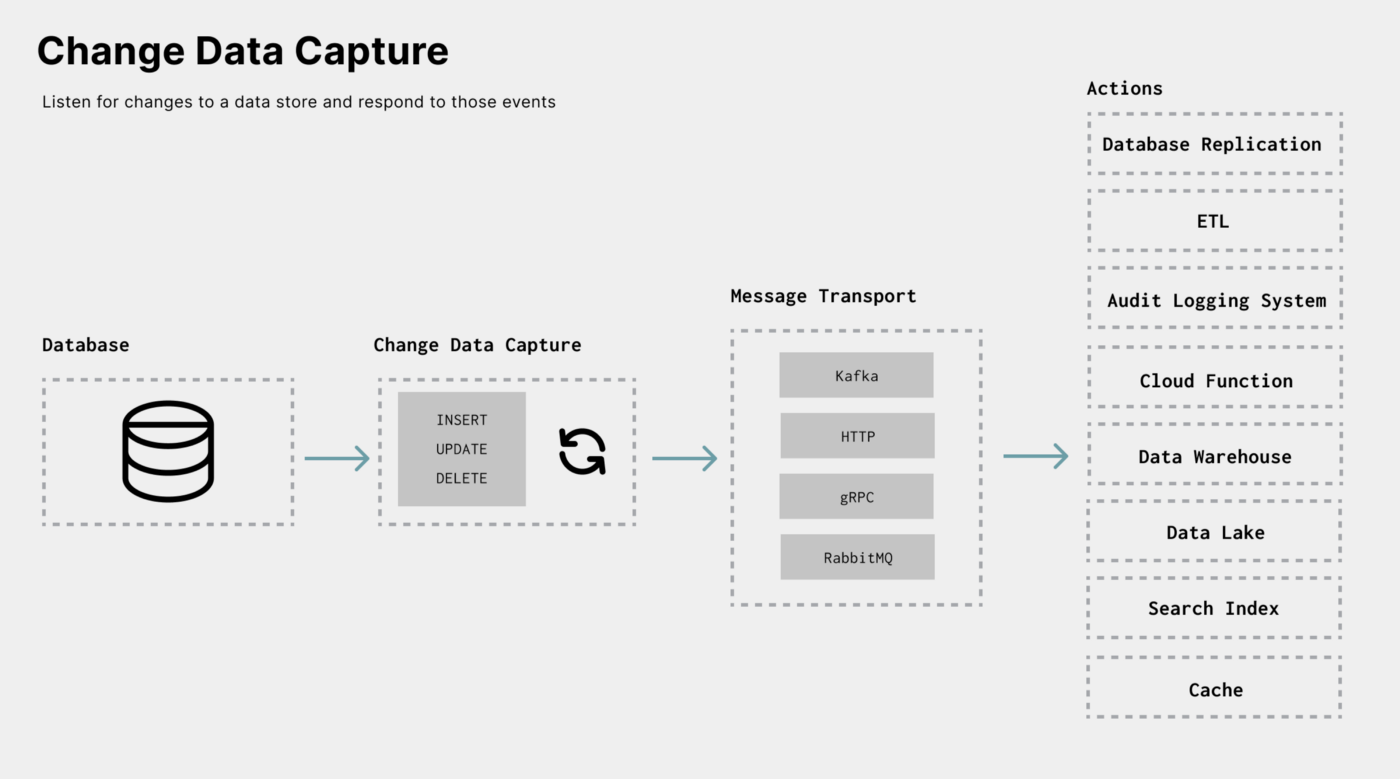
This is part two of a series on Change Data Capture (CDC). In part one,we defined change data capture, explored how data is captured, and the pros and cons of each capturing method. In this article, let’s discuss the use cases of CDC and look at the tools that help you add CDC into your architecture.
Change Data Capture helps enableevent-driven applications. It allows applications to listen for changes to a database, data warehouse, etc., and act upon those changes.
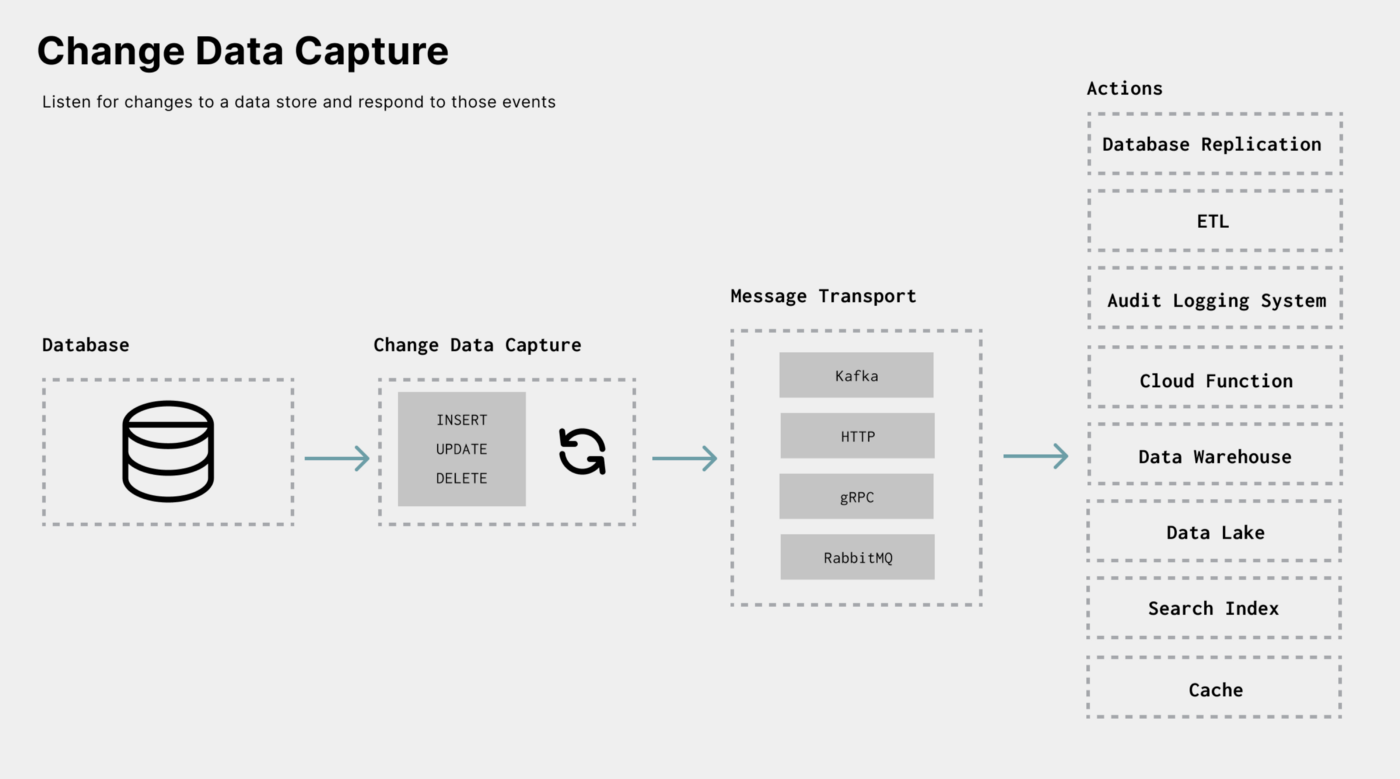
At a high level, here are the use cases and architectures that arise from acting on data changes:
- Extract, Transform, Load (ETL): Capturing every change of one datastore and applying these changes to another allows for replication (one-time sync) and mirroring (continuous syncing).
- Integration and Automation: The action taken on data change events can automate tasks, trigger workflows, or even execute cloud functions.
- History: When performing historical analysis on a dataset, having the current state of the data and all past changes gives you complete information for a higher fidelity analysis.
- Alerting: Most of the time, applications send an event to a user whenever the data they care about changes. CDC can be the trigger for real-time alerting systems.
Let’s explore.
Extract, Transform, Load
As of date, one of the most common use cases for CDC is Extract, Transform, Load (ETL). ETL is a process in which you are capturing data from one source (extract), processing it in some way (transform), and sending it to a destination (load).
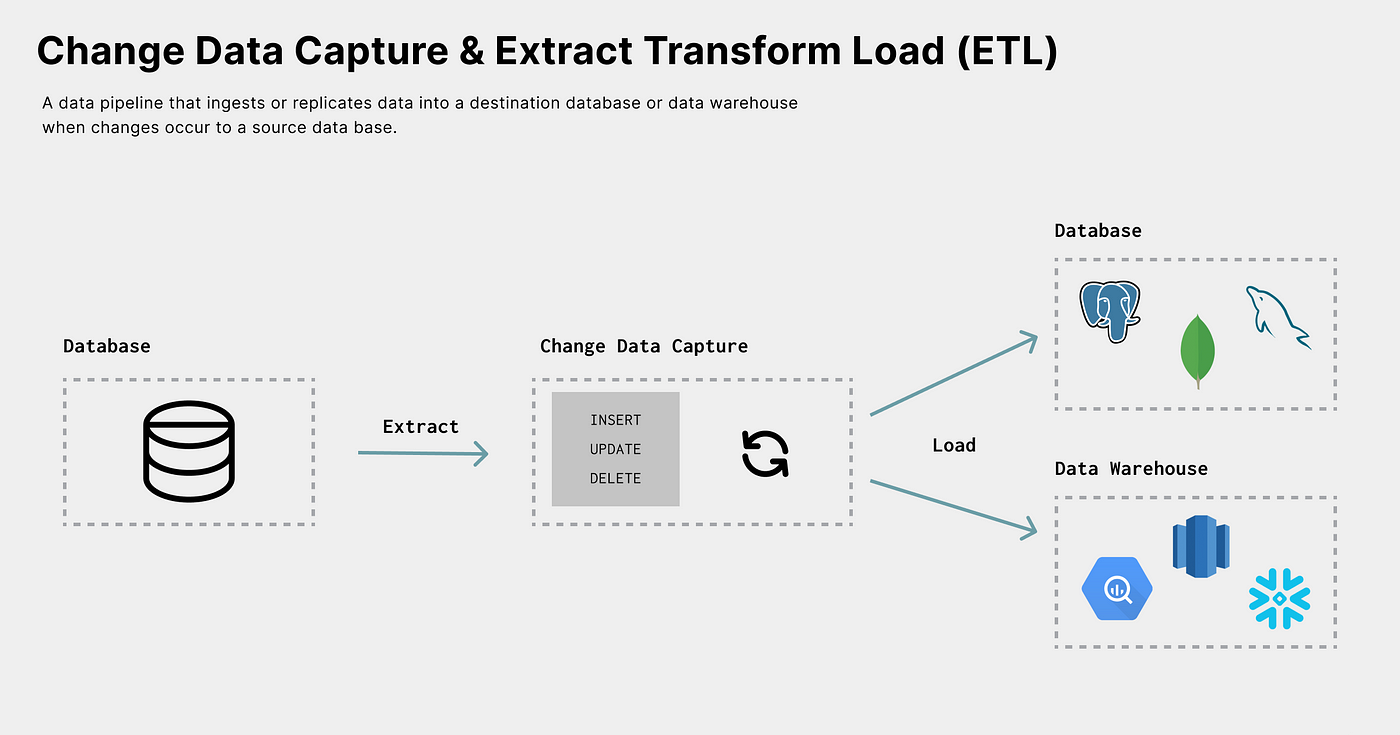
Data replication (one-time sync) and mirroring (continuous replication) are great examples of ETL processes. ETL is an umbrella term that encompasses very different use cases such as:
- Ingesting data from a database into a data warehouse to run analytic queries without impacting production.
- Keeping caches and search index systems up-to-date
Not only can CDC help solve these use cases, but it’s also the best way to solve these problems. For example, to mirror data to a data warehouse, you must capture and apply anychanges as they happen to the source database. As discussed withStreaming Replication Logs in part one of the series, CDC is used by databases to keep standby instances up-to-date for failover because it’s effective and scalable. When tapping into these events in a wider architecture, your data warehouse can be as up-to-date as a standby database instance used for disaster recovery.
Keepingcaches and search index systems up-to-date are also ETL problems and great CDC use cases. Large applications created today are comprised of many different data stores. For example, certain architectures will leverage Postgres, Redis, and Elasticsearch as a relational database, caching layer, and search engine. All are systems of record designed for specific data use cases, but data needs to be mirrored in each store.
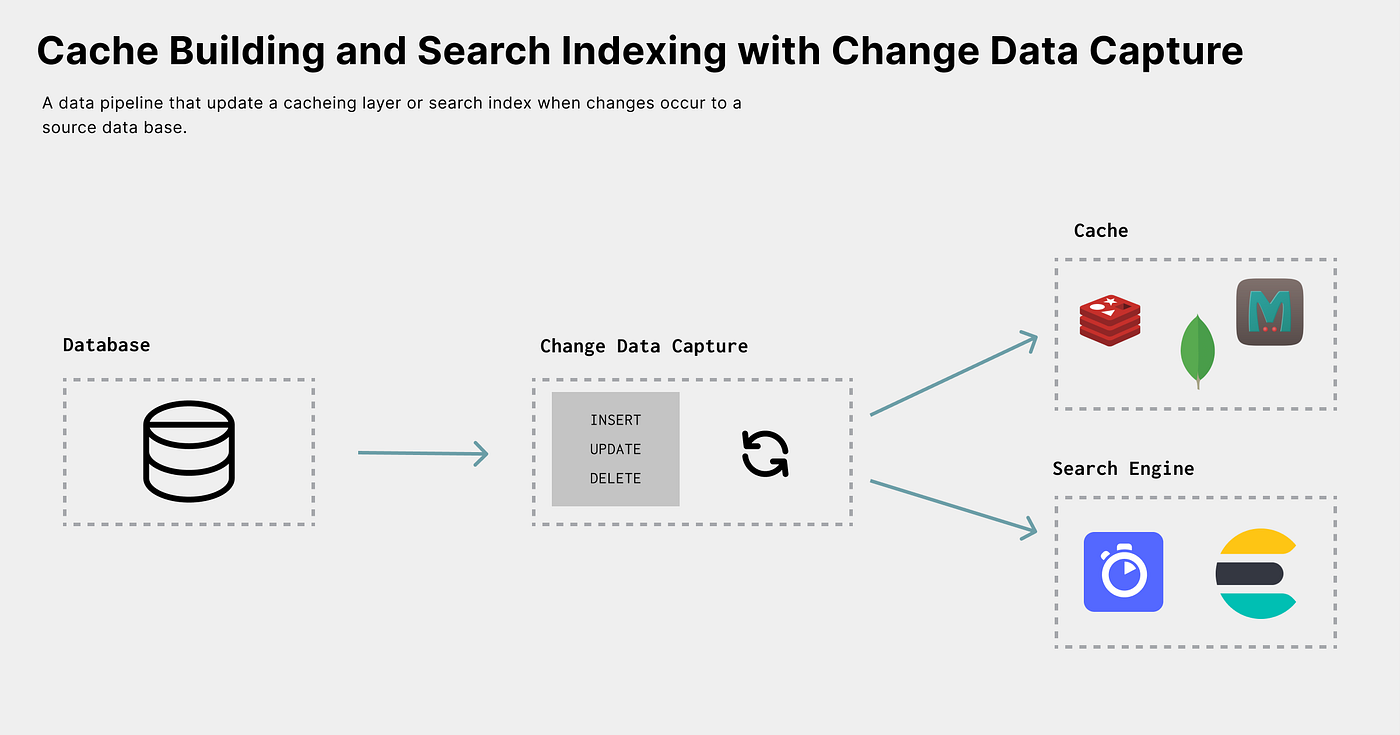
You never want a user to search for a product and then find out it longer exists. Stale caches and search indexes lead to horrible user experiences. CDC can be used to build data pipelines that keep these stores in sync with their upstream dependencies.
In theory, a single application could write to Postgres, Redis, and Elasticsearch simultaneously, but “Dual Writes” can be tough to manage and can lead to out-of-sync systems. CDC offers a stronger, easier-to-maintain implementation. Instead of adding the logic to update indexes and caches to a single monolithic application, one could create an event-driven microservice that can be built, maintained, improved, and deployed independently from user-facing systems. This microservice can keep indexes and caches up to date to ensure users operate on the most relevant data.
Integration and Automation
The rise of SaaS has exploded the number of tools that generate data or need to be updated with data. CDC can provide a better model for keeping Salesforce, Hubspot, etc., up to date and allow automation of business logic that needs to respond to those data changes.
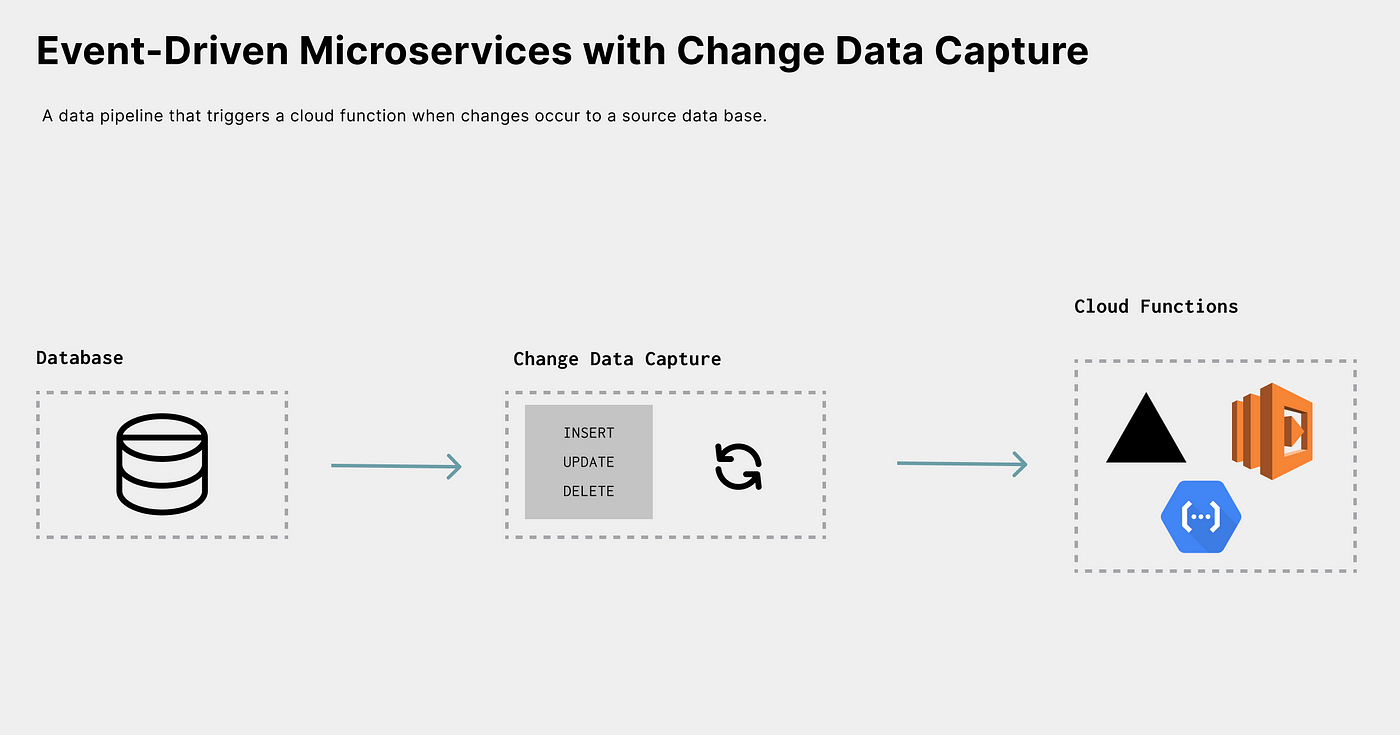
Each of the use cases we described above sends data to a specific destination. However, the most powerful destination is a cloud function. Capturing data changes and triggering a cloud function can be used to perform every use case mentioned (and not) in this article.
Cloud functions have grown tremendously because there are no servers to maintain; they automatically scale and are simple to use and deploy. This popularity and usefulness have been apparent and proven in architectures like the JAMStack. CDC fits perfectly with this architecture model.
Today, Cloud functions are triggered by an event. This event could be when afile is uploaded to Amazon S3 or an HTTP request. However, as you might have guessed, this trigger event could be emitted by a CDC system.
For example, here is an AWS Lambda Function to accept a data change event andperform Algolia search indexing:
const algoliasearch = require("algoliasearch");
const client = algoliasearch(process.env.ALGOLIA_APP_ID, process.env.ALGOLIA_API_KEY);
const index = client.initIndex(process.env.ALGOLIA_INDEX_NAME);
exports.handler = async function(event, context) {
console.log("EVENT: \\n" + JSON.stringify(event, null, 2))
const request = event.Records[0].cf.request;
// Accessing the Data Record
//
const body = Buffer.from(request.body.data, 'base64').toString();
const { schema, payload } = body;
const { before, after, source, op } = payload;
if (req.method === 'POST') {
try {
// if read, create, or update operation create o update index
if (op === 'r' || op === 'c' || op === 'u') {
console.log(`operation: ${op}, id: ${after.id}`)
after.objectID = after.id
await index.saveObject(after)
} else if (op === 'd') {
console.log(`operation: d, id: ${before.id}`)
await index.deleteObject(before.id)
}
return res.status(200).send()
} catch (error) {
console.log(`error: ${JSON.stringify(error)}`)
return res.status(500).send()
}
}
return context.logStreamName
}Every time this function is triggered, it will look at the data change (op) and perform the equivalent action in Algolia. For example, if a delete operation occurs in the database, we can perform a[deleteObject](https://www.algolia.com/doc/api-reference/api-methods/delete-objects/)in Algolia.
Functions that respond to CDC events can be small and simple. But, CDC — along with event-based architectures — can simplify otherwise very complex architectures as well.
For example, implementing Webhooks as a feature within your application becomes a more straightforward problem with CDC. Webhooks allow users to trigger aPOST request when certain events occur, typically data changes. For example, withGithub, you can trigger a cloud function when a pull request is merged. A merged pull request is anUPDATE operation to a data store, which means a CDC system can capture this event. Generally, most webhook events can be translated toINSERT``UPDATE andDELETE operations that a CDC system can capture.
History
You may not want to act on the CDC event but only store the raw changes in some cases. Using CDC, a data pipeline can store all change events to a cloud bucket for long-term processing and analysis. The best place to store the data for historical analysis is within a cloud bucket, referred to as a data lake.
A data lake is a centralized store that allows you to store all your structured and unstructured data at any scale. Data lakes typically leverage cloud object bucket solutions like Amazon S3 orDigital Ocean Spaces.
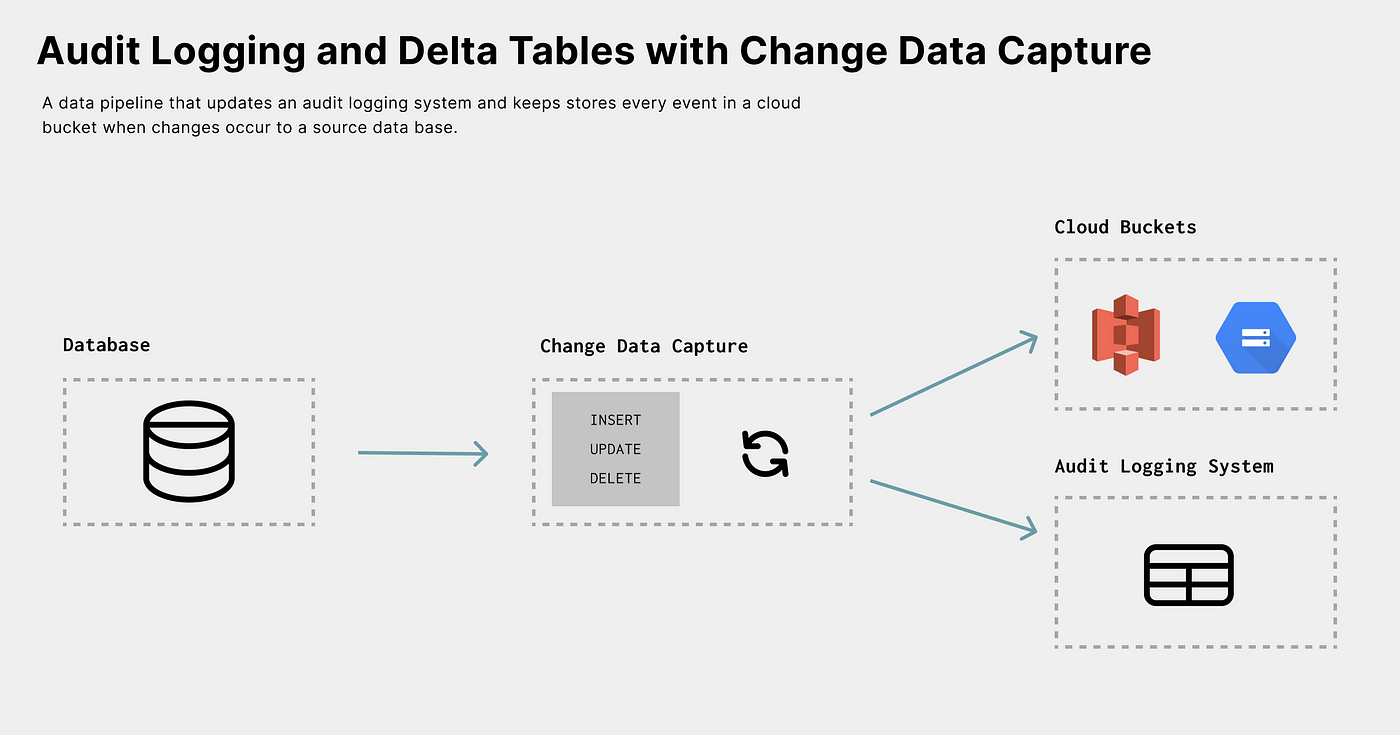
For example, once the data is in a data lake, SQL query engines like Amazon Presto can run analytic queries against the change datasets.
While storing the raw changes, you not only have the current state of the data, you have all the previous states (historical). That’s why CDC adds a ton of value to historical analysis.
Having historical data allows you to support disaster recovery efforts and also allows you to answer retroactive questions about your data. For example, let’s say your team redefined how Monthly Active Users (MAU) are calculated. With the complete history of a user data set, one could perform the new MAU calculations based on any date in the past and compare the results to the current state.
This rich history also has user-facing value. Audit logs and activity logs are features that display data changes to users.
Capturing and storing change events offers a better architecture when these features are implemented. Like in Webhooks, audit logs and activity logs are rooted in operations that a CDC system can capture.
Alerting
The job of any alerting system is to notify a stakeholder of an event. For example, when you receive a new email notification, you are notified of anINSERT operation to an email data store. Typically, most alerts are related to a change in a data store, which means that CDC is great for powering alerting systems.
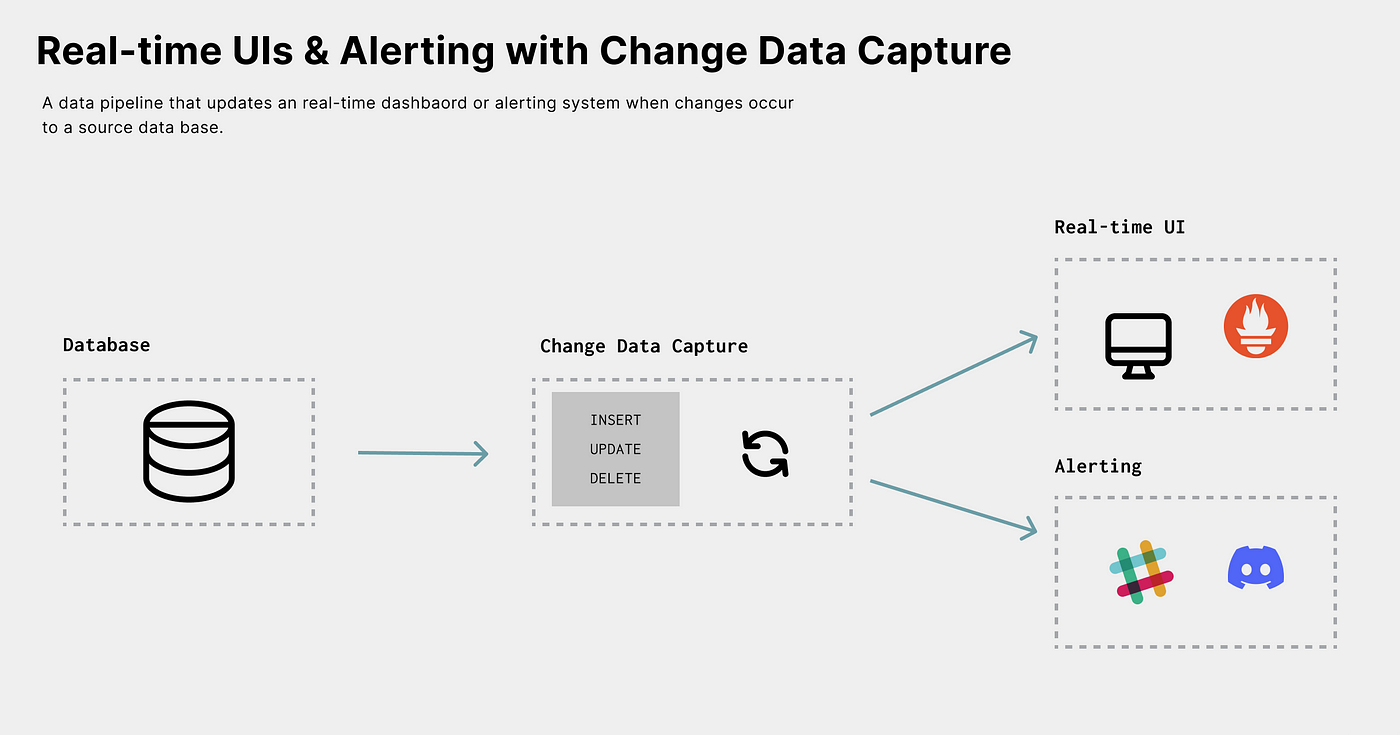
For example, let’s say you have an eCommerce store. After enabling CDC on a table of purchases, you could capture the change event and notify the team by performing a Slack alert when there are new purchases.
Just like audit or activity logs, notifications powered by CDC can not only provide information about the event that occurred but also provide details of the change itself:
Tom has updated the title from "Meeting Notes" to "My New Meeting."This alerting behavior also has internal value. From an infrastructure monitoring perspective, CDC events can provide insight into how users interact with your application and data. For example, you could see when and how users add, update, or delete information. This data can be sent toPrometheus UI to monitor and act on this information.
Getting Started with CDC
Inpart one, we talked about the various ways CDC is commonly implemented:
- Polling
- Database Triggers
- Streaming Logs
These can all be used to build the use cases we’ve discussed in this article. Best of all, since CDC focuses on the data, the process is programming language agnostic and can be integrated into most architectures.
Polling and Triggers
When using polling or database triggers, there is no overhead and nothing to install. You can get started by building your queries to poll or by leveraging your databases’ triggers if they are supported.
Streaming Logs
Databases use streaming replication logs for backup and recovery, which means that most databases provide some CDC behavior out of the box. How easy it is to tap into these events depends on the data store itself. The best place to get started is by digging into your database’s replication features. Here are some replication log resources for some of the most popular databases:
To get started with streaming logs, the answer is tightly coupled to the database in question. In future articles, I’ll explore what it looks like for each of these.
Implementing any of these directly does take some time, planning, and effort. If you’re trying to get started with CDC, the lowest barrier to entry is adopting a CDC tool that knows how to communicate and capture changes from the data stores you use.
Change Data Capture Tools
Here are some great tools for you to evaluate:
Debezium
Debezium is by far the most popular CDC tool. Its well-maintained, open-sourced and built on top of Apache Kafka. It supports MongoDB, MySQL, PostgreSQL, and more databases out of the box.
At a high level, Debezium hooks into the replication logs of the database and emits the change events into Kafka. You can even run Debezium standalone without Kafka.
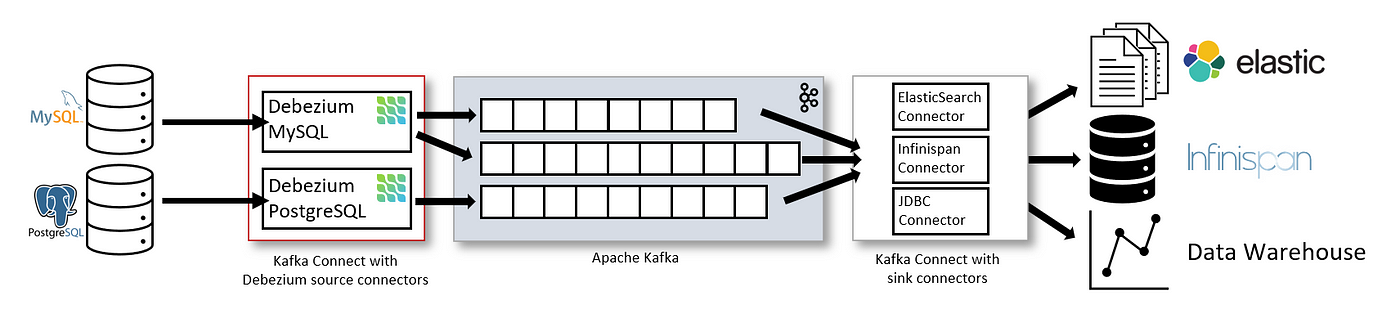
What’s really nice is that Debezium is all configuration-based. After installing and configuring Debezium, you can configure connections to your datastore using a JSON-based configuration:
{
"name": "fulfillment-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "192.168.99.100",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname" : "postgres",
"database.server.name": "fulfillment",
"table.include.list": "public.inventory"
}
}Once connected, Debezium will perform an initial snapshot of your data and emit change events to a Kafka Topic. Then, services canconsume the topics and act on them.
Here are some great places to get started with Debeizium:
Meroxa
Meroxa is a real-time data orchestration platform that gives you real-time infrastructure. Meroxa removes the time and overhead associated with configuring and managing brokers, connectors, transforms, functions, and streaming infrastructure. All you have to do is add your resources and construct your pipelines. Meroxa supports PostgreSQL, MongoDB, Microsoft SQL Server, and more.
CDC pipelines can be built in a visual dashboard or using the Meroxa CLI:
# Add Resource
$ meroxa resource add my-postgres --type postgres -u postgres://$PG_USER:$PG_PASS@$PG_URL:$PG_PORT/$PG_DB # Add Webhook
$ meroxa resource add my-url --type url -u $CUSTOM_HTTP_URL # Create CDC Pipeline$ meroxa connect --from my-postgres --input $TABLE_NAME --to my-urlI can’t wait to see what you build. 🚀
If you have any questions or feedback, I’d love to hear them. You can:



