It’s easy to see the appeal of MongoDB, so it’s no surprise it's so popular. With the advent of numerous managed providers, the operational burden has also been minimized.
One problem that has not really been solved that well, is the ability to pull data out of MongoDB efficiently and in real-time. In our example, we will be moving data from MongoDB to Kafka in real-time.
This post walks through building a Turbine Data Stream Processing App to do just that.
How it works
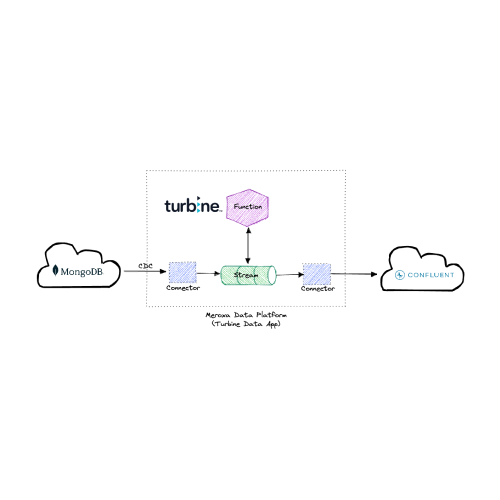
The Turbine Data Stream Processing App works by creating a CDC (Change Data Capture) connector from the platform to a MongoDB Atlas-hosted database. This connector receives changes in real-time and publishes them into the Meroxa Platform in the form of a stream.
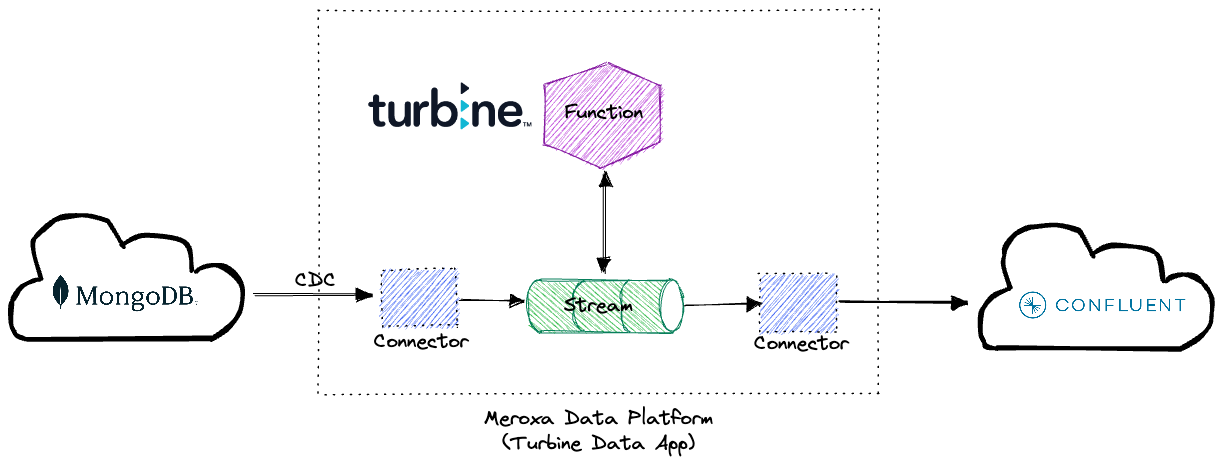
The Turbine library allows us to write functions to transform and manipulate that data easily. In fact, we can do anything we normally do with a general programming language, such as calling APIs or importing packages and libraries.
The Turbine framework does the heavy lifting to make that stream of data available to your custom function in a way that’s familiar and easy to reason about.
In this example, we’re simply filtering out some of the data and pass through the rest to the downstream Kafka cluster.
Requirements
Setup
We’ll be using MongoDB Atlas and Confluent Cloud in this example. Both services provide free trials and/or free plans making it easy for you to create accounts and follow along if you don’t already have one.
Once you’ve created a MongoDB Atlas account, you can create a free shared cluster. This will be enough for the purposes of testing out this application.
💡 Refer to the MongoDB Atlas documentation here to set up a free shared cluster.
Similarly, you can use the *basic *****Kafka plan on Confluent Cloud.
💡 Refer to Meroxa’s guide here to set up a Confluent Cloud account
Next, we’ll initialize the Data Stream Processing App via the Meroxa CLI. If you need to create an account on Meroxa, you can request a demo. Once you have created a Meroxa account and set up the Meroxa CLI you need to add your resources and initialize a Turbine Data Stream Processing App.
First, we will add the resources. Below, we are using the Meroxa CLI to add our MongoDB Atlas instance and Confluent Cloud instance. Alternatively, you can also do this via the Meroxa Dashboard.
$ meroxa resource create mdb \\
--type mongodb \\
--url "mongodb://$MONGO_USER:$MONGO_PASS@$MONGO_URL:$MONGO_PORT"$ meroxa resource create cck \\
--type confluentcloud \\
--url "kafka+sasl+ssl://$API_KEY:$API_SECRET@$BOOTSTRAP_SERVER?sasl_mechanism=plain" \\Then, we create a new Turbine App project (in Go) in the directory marketplace-notifier.
$ meroxa apps init --lang go marketplace-notifier 💡 If you prefer to use another language, Meroxa also supports Javascript, Python, and Ruby with support for many more languages coming!
Now we’re all set to start implementing our Data Stream Processing App.
Data Stream Processing App
All Turbine Data Stream Processing Apps consist of two main parts. The pipeline topology part (where we define the components that make up the data pipeline, including Resources, Sources, Destinations, Processors etc…) and the function part (where we can implement any custom logic that’s needed).
func (a App) Run(v turbine.Turbine) error {
// reference the MongoDB resource that was created on the platform. In this case I created "mdb".
source, err := v.Resources("mdb")
if err != nil {
return err
}
// pull records from the "events" collection.
rr, err := source.Records("events", nil)
if err != nil {
return err
}
// apply the "FilterInteresting" processor to those records.
res := v.Process(rr, FilterNotify{})
// reference the Kafka resource that was created on the platform. In this case I created "cck".
dest, err := v.Resources("cck")
if err != nil {
return err
}
// write out the resulting records into the collection (or __Topic__ in the case of Kafka). In this case I'm writing
// out to the Topic "interesting_events".
err = dest.WriteWithConfig(res, "notifications", nil)
if err != nil {
return err
}
return nil
}Here’s the entirety of the Run method. Here we can see that we’re grabbing references to the MongoDB resource mdb we created above, pulling records out of it from the collection events, piping those records through a processor FilterNotify and then ultimately writing it out into the topic notifications on the Kafka resource cck (also created above).
Processing Data
The actual business logic of our Turbine Application is relatively straightforward. We loop through the slice of records and if a particular event includes a “vip:true” then we call out to an external service to notify the appropriate user.
// FilterInteresting looks for "interesting" events and filters out everything else.
// For this example, __interesting__ events are any events where an event is associated with a VIP user.
type FilterInteresting struct{}
func (f FilterInteresting) Process(stream []turbine.Record) []turbine.Record {
var interestingEvents []Event
for _, r := range stream {
ev, err := parseEventRecord(r)
if err != nil {
log.Printf("error: %s", err.Error())
break
}
if isInteresting(ev) {
interestingEvents = append(interestingEvents, ev)
}
}
if len(interestingEvents) > 0 {
recs, err := encodeEvents(interestingEvents)
if err != nil {
log.Printf("error: %s", err.Error())
}
return recs
}
return []turbine.Record{}
}
// Event represents the Event document stored in MongoDB.
type Event struct {
UserID string `json:"user_id"`
Activity string `json:"activity"`
VIP bool `json:"vip"`
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
DeletedAt time.Time `json:"deleted_at"`
}Demo
Meroxa allows developers to test their code locally via fixtures. Fixtures are a JSON representation of the data that the Turbine library will process. In our example, we have a single record to represent what the Data Stream Processing App will read from MongoDB and write to Kafka if the FilterInteresting function returns an “interesting” event. To run locally, you can run the following command:
$ meroxa apps run We will get the following output:
Here we can see that 1 record was written to the cck resource, which matched our criteria in our code. Once you are happy with your code we can deploy the app live to read and write with your actual resources. To deploy your app live you can run the following commands:
$ git add .$ git commit -m "Initial Commit" $ meroxa apps deploy 💡 For more information on deployment, you can refer to the Meroxa Docs here.
Once your app is deployed, you will see that every record in your MongoDB has been processed and has been written to your Kafka topic. As records come into your data source (MongoDb in this example), your Turbine app running on the Meroxa platform will process each record in real-time.
Meroxa sets up all the connections and removes the complexities, so you, the developer, can focus on the important stuff.
Next Steps
Now that the Turbine Data Stream Processing App has been deployed we can extend the app with additional Destinations. This allows us to also persist the end results into an audit table or data warehouse for additional tracking and analysis.
To add additional Destinations you would simply create the resource, reference it (e.g. app.resource("auditdb")) and then write to that as well.
💡 You can add additional destinations just like we added MongoDB and Confluent Cloud above using meroxa resource create . See Resources here.
We could also easily extend the processing logic by adding whatever functionality is required into our custom function. This could be as straightforward as reformatting fields or as sophisticated as importing 3rd party packages and leveraging those to transform the records or hitting external APIs to enrich the data.
💡 For an example on using API’s in Turbine you can read our blog post on APIs here.
Have questions or feedback?
If you have questions or feedback, reach out directly by joining our community or by writing to support@meroxa.com.
Happy Coding 🚀




