
Building AI-powered applications can be challenging, especially when dealing with raw data that needs extensive preprocessing before it can be used for training machine learning models. If you've ever tried to set up an end-to-end pipeline for fine-tuning a language model like Llama, you know the headaches involved in data preparation, model training, and deployment.
In this comprehensive guide, we'll tackle a common challenge faced by ML engineers and data scientists:
Problem Statement: Imagine you have a collection of raw files sitting in an S3 bucket. Your goal is to build a production-ready system that can automatically convert these files into JSONL format, ensure data consistency through transformations, fine-tune a Llama language model, and deploy an API for real-time recommendations. The catch? Everything needs to be automated and production-ready.
We'll show you how to solve this using a powerful combination of tools: Meroxa for handling data streaming and transformations, Hugging Face's Trainer API for model fine-tuning, and Docker/Heroku for deployment. By the end of this guide, you'll have a robust, automated pipeline that takes you from raw data to serving predictions in production.
Overview Diagram: Solution Architecture
The following Mermaid diagram outlines the overall solution:

This diagram shows how raw files are ingested from S3, converted to JSONL using a custom processor, then further transformed, stored back in S3, and used to trigger a remote training job. The resulting fine-tuned model is then served via a recommendations API.
Prerequisites & Environment Setup
Before you begin, ensure you have:
-
Python Environment:
-
Install Python 3.8+.
-
Create and activate a virtual environment:
-
Install required packages:
-
-
Meroxa Account & S3 Setup:
- Sign up and log in to Meroxa.
- Configure two AWS S3 buckets: one for raw data (e.g.,
raw-data-bucket) and one for processed data (e.g.,processed-data-bucket). - Ensure your environment (or cloud server) has proper AWS credentials or IAM roles to access these buckets.
-
Docker & Heroku CLI:
- Install Docker.
- Install the Heroku CLI.
Step 1. Setting Up a Single Meroxa Pipeline
Meroxa pipelines are defined via a YAML configuration file that specifies sources, processors, and destinations. In this pipeline, we:
-
Ingest Raw Files:
Pull raw files (e.g., CSV, text files) from an S3 bucket.
-
Convert to JSONL:
Use a custom processor (
convert_to_jsonl.js) to convert these raw files into JSONL format. -
Custom Transformation:
Apply a second custom processor (
transform_data.js) to further standardize each record (e.g., converting all keys to lowercase). -
Store & Trigger:
Write the processed JSONL data back to an S3 bucket and trigger an HTTP endpoint (via a
webhook.httpprocessor) to start a remote fine-tuning job.
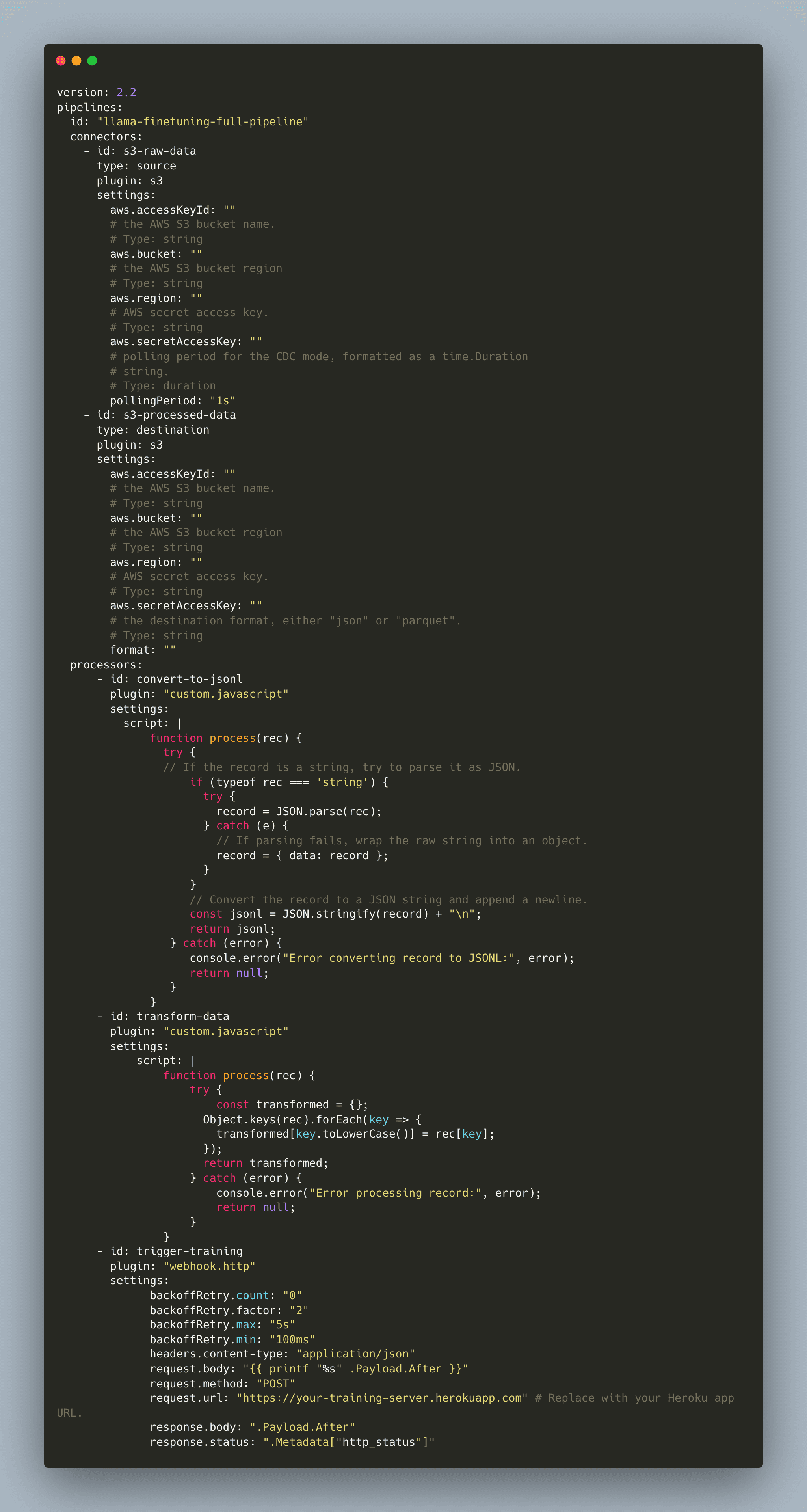
Meroxa Pipeline YAML
Create a file named pipeline.yaml with the following content:
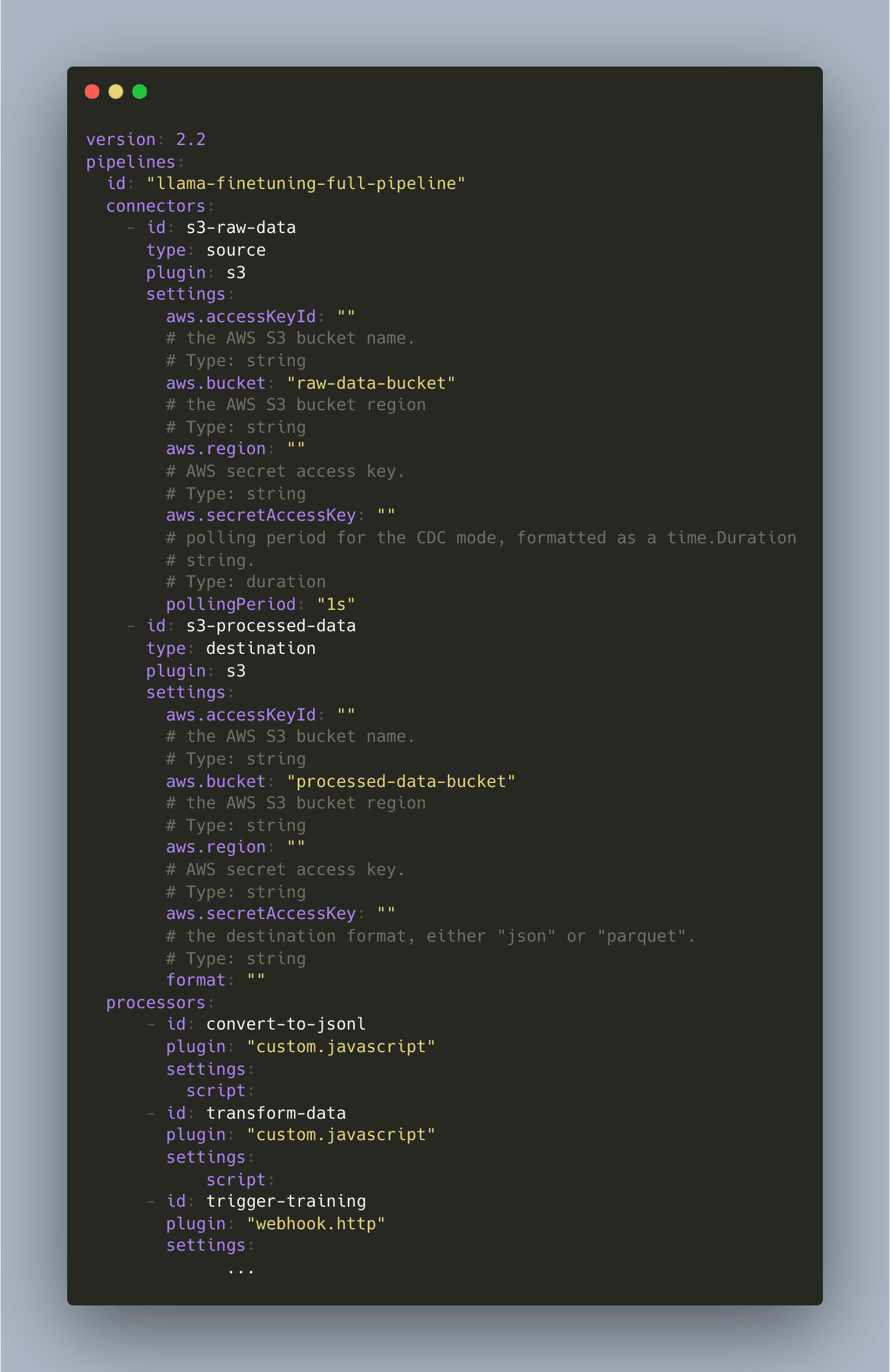
Instructions:
- Replace
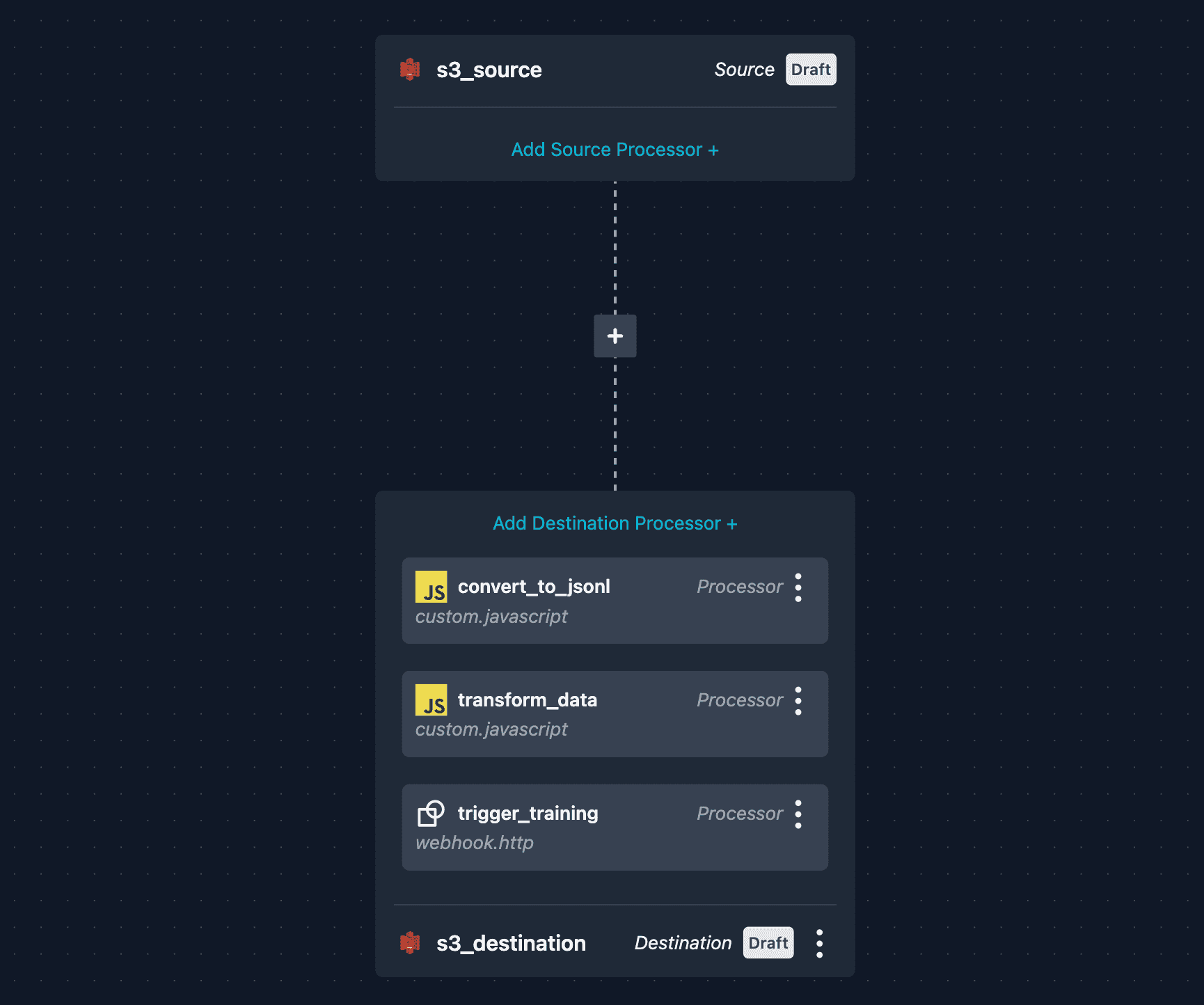
raw-data-bucketandprocessed-data-bucketwith your actual S3 bucket names. - Upload this YAML via the Meroxa dashboard by navigating to Pipelines → Create Pipeline and pasting or uploading the file. Your pipeline should look like this in the dashboard:
Step 2. Writing Custom Processors for Meroxa
Meroxa requires custom processors to be written in JavaScript. We need three processors for our workflow.
2.1. JSONL Conversion Processor (convert_to_jsonl.js)
This processor converts a raw record into a JSONL-formatted string before it’s stored in S3.

2.2. Data Transformation Processor (transform_data.js)
This processor further cleans the data by converting all keys to lowercase.
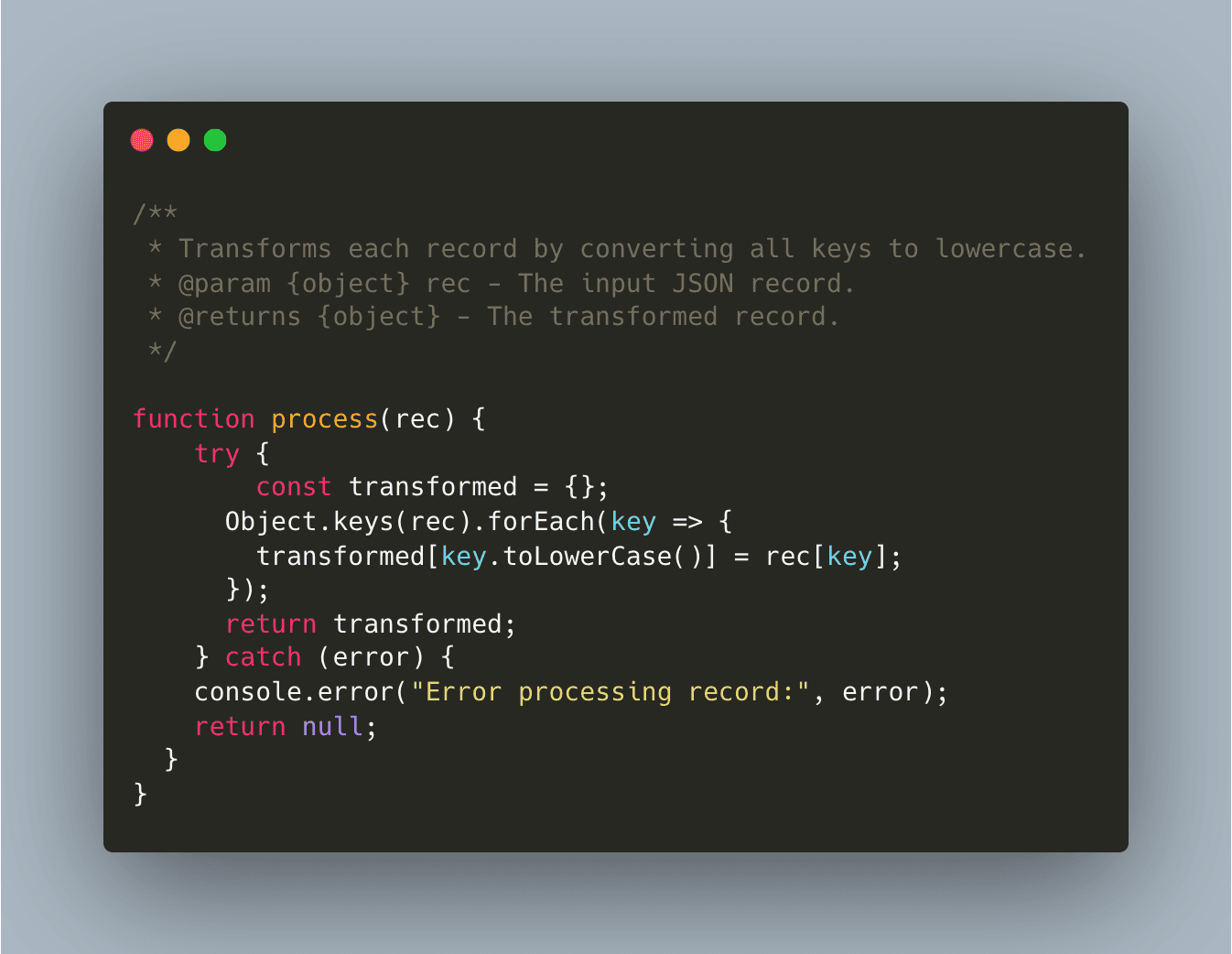
2.3. Training Trigger webhook.http Processor
This processor sends an HTTP POST request to your training server endpoint when new processed data is available.
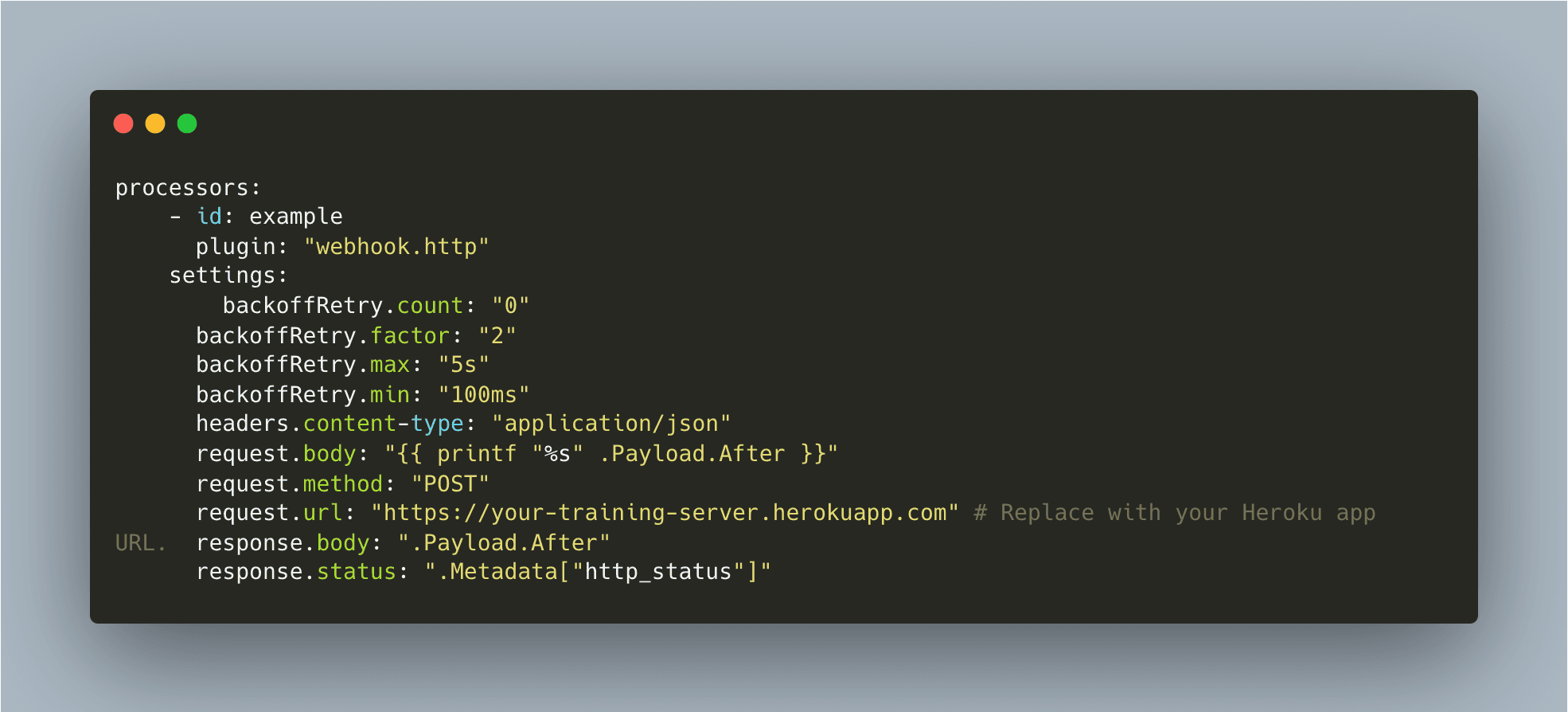
Here’s the completed pipeline.yaml file:
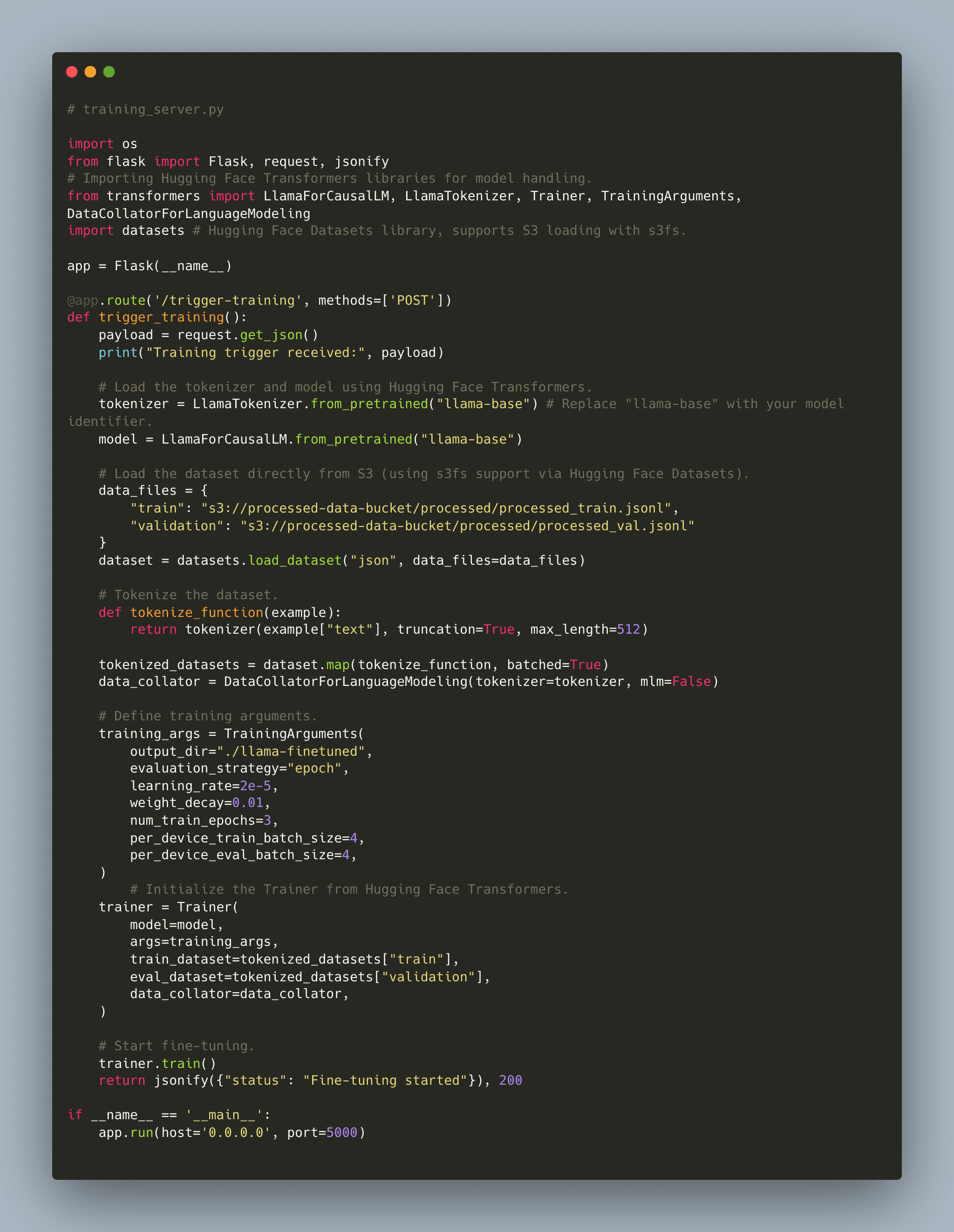
Step 3. Remote Fine-Tuning on a Training Server
When the Meroxa pipeline triggers your training server, it should load the processed JSONL data directly from S3 and begin fine-tuning the Llama model using Hugging Face’s Trainer API.
Remote Training Server Code
Below is a Flask app that exposes a /trigger-training endpoint. Upon receiving a POST request, it loads the dataset from S3 (using s3fs support via the datasets library), tokenizes the data, and starts fine-tuning.
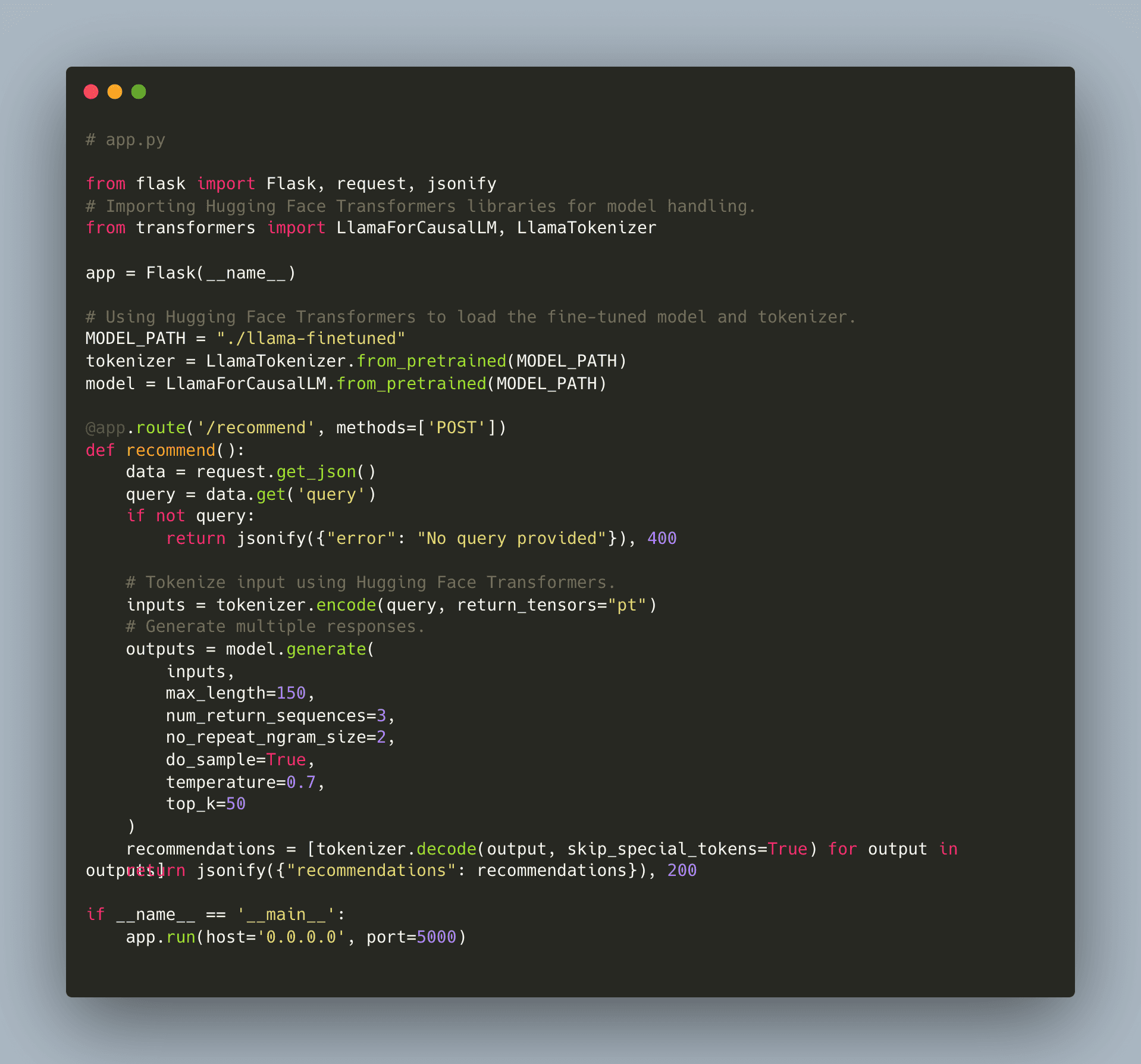
Step 4. Building and Deploying the Recommendations API
After fine-tuning, you’ll serve your model via an API. The following Flask application defines a /recommend endpoint that accepts a query and returns recommendations generated by your fine-tuned Llama model.
Recommendations API Code
Step 5. Deployment with Docker and Heroku
We’ll now containerize both the training server and the recommendations API and deploy them on Heroku as separate applications with its own Docker image. This approach keeps the deployments isolated and simplifies scaling and monitoring.
Prepare Your Codebase
Assume your project repository has two subdirectories:
training/– containstraining_server.pyand itsDockerfile.recommendations/– containsapp.py(for the recommendations API) and itsDockerfile.
Each subdirectory has its own requirements.txt and Dockerfile.
5.1. Create a requirements.txt
For both services, create a requirements.txt file:

5.2. Create a Dockerfile for the Recommendations API (recommendations/Dockerfile):
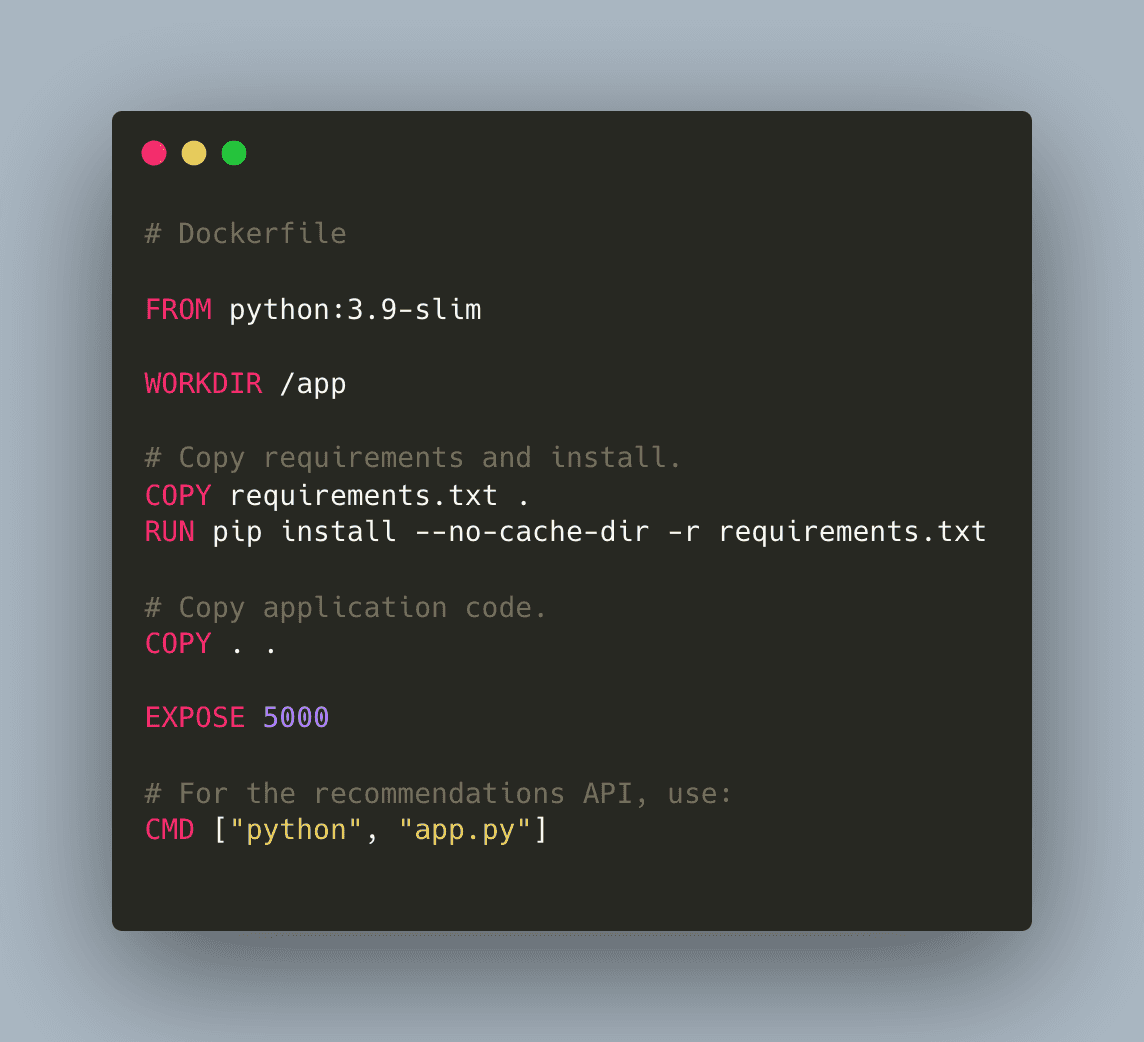
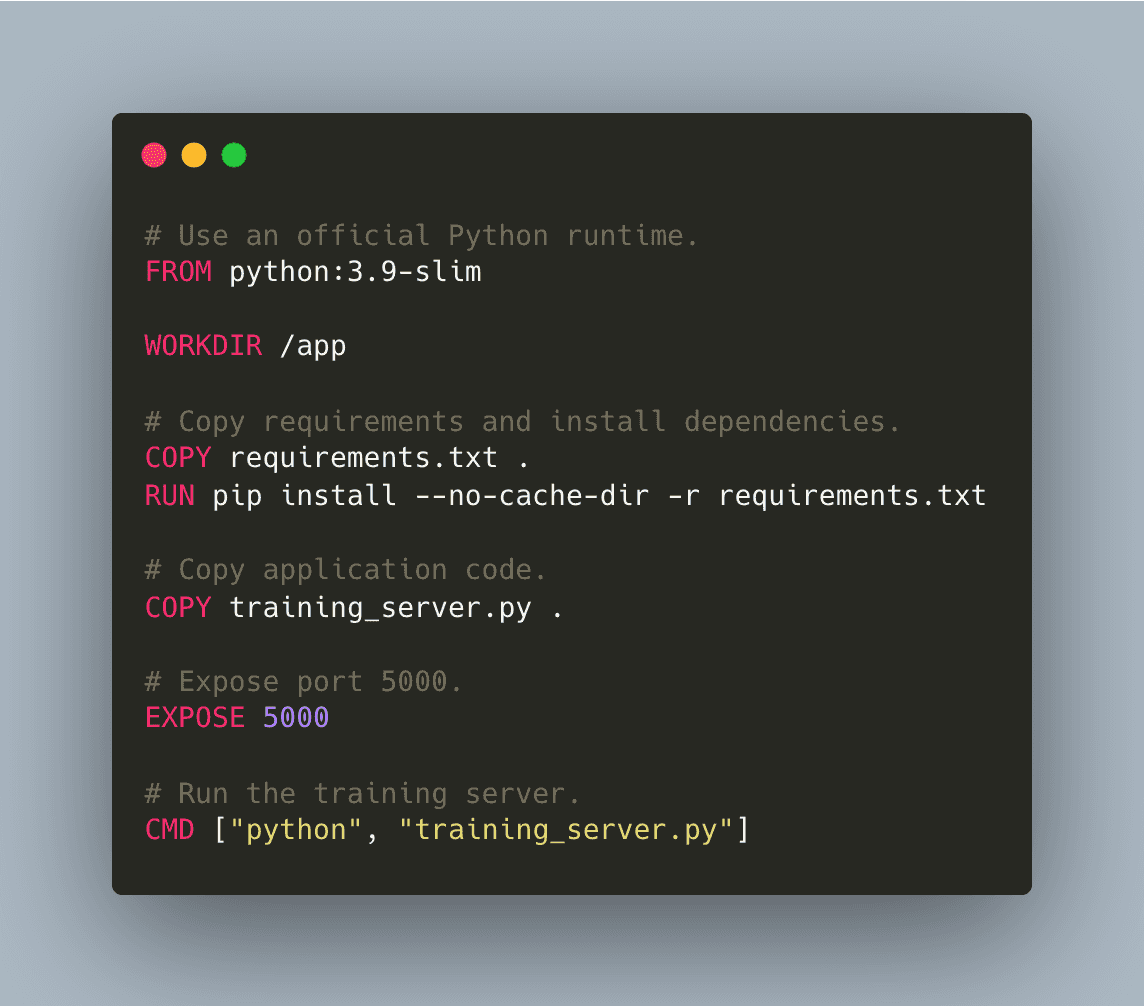
5.2.1 Create a Dockerfile for the Training Server (training/Dockerfile):
5.3. Deploying to Heroku
Use the following CLI commands to deploy your API endpoints via Docker to Heroku:
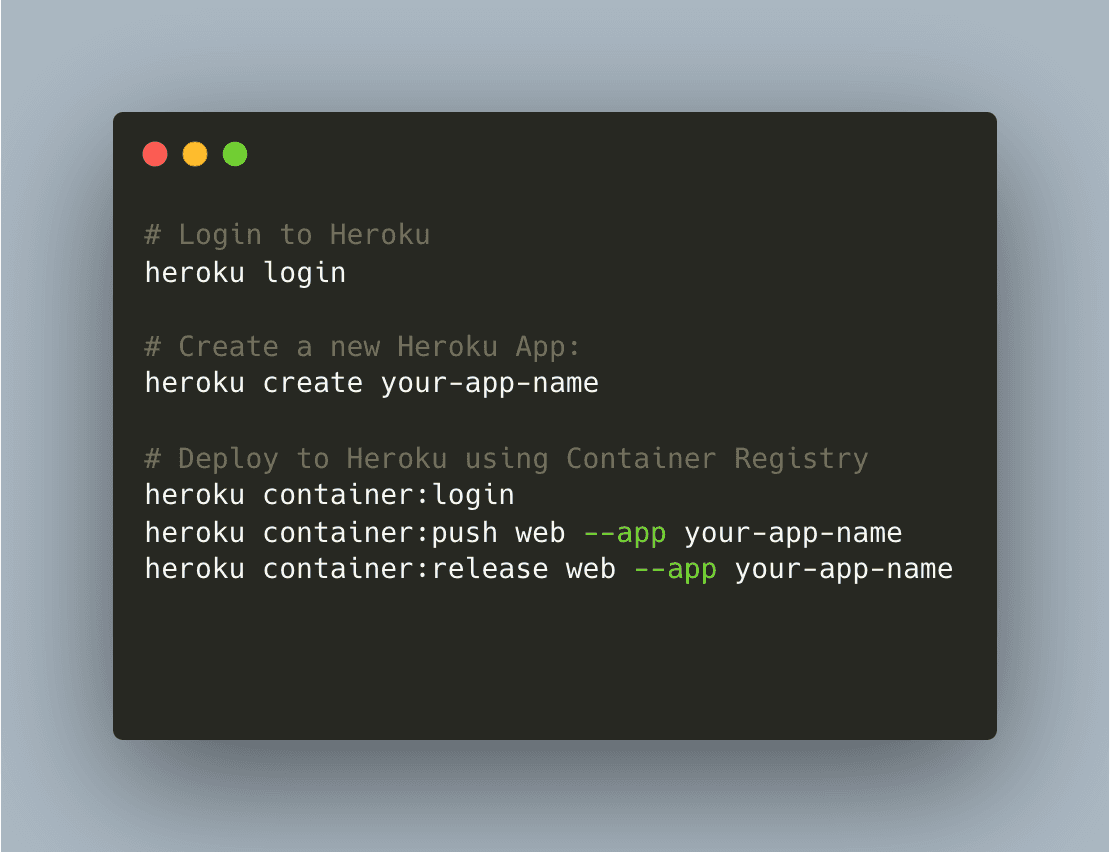
Scale and Monitor Your Heroku Apps:
Your app will be available at https://your-app-name.herokuapp.com.
-
For the training server, ensure the
/trigger-trainingendpoint is accessible; for the recommendations API, use/recommend.- Use the Heroku dashboard or CLI commands (e.g.,
heroku ps:scale web=1 --app your-app-name) to adjust the number of dynos based on your traffic requirements. - Heroku provides built-in logging (
heroku logs --tail --app your-app-name) and you can integrate additional monitoring tools if needed.
- Use the Heroku dashboard or CLI commands (e.g.,
Repeat these steps for each service by creating separate Heroku apps or configuring them as separate processes within one app.
Conclusion
Congratulations! You've just learned how to build an amazing AI pipeline that takes your model from data to deployment. Here's what we accomplished:
- Built a powerful Meroxa pipeline that seamlessly handles your data - from raw files in S3 all the way through to processed JSONL format, ready for training
- Created a smart training server that automatically fine-tunes your Llama model when new data arrives
- Set up a production-ready API that serves real-time recommendations using your fine-tuned model
- Learned how to deploy everything to the cloud using Docker and Heroku, making your solution production-ready
With this setup, you now have an automated system powered by Meroxa's Conduit Platform that handles everything from data processing to model deployment. The best part? It's scalable and ready to grow with your needs.
Now it's your turn to build something amazing! Happy coding! 🚀

- Share Streamlining AI: How to Fine-Tune Llama in Real Time with Meroxa, Hugging Face, and Heroku on Facebook

- Share Streamlining AI: How to Fine-Tune Llama in Real Time with Meroxa, Hugging Face, and Heroku on Twitter

- Share Streamlining AI: How to Fine-Tune Llama in Real Time with Meroxa, Hugging Face, and Heroku on LinkedIn

