Hey, data streaming fans! The Conduit team is happy to inform you that Conduit v0.12 has just been released! As we prepare for the launch of Conduit v1, one of the key things we’ve been focusing on is how to make our pipelines more resilient. We believe this is a crucial step in preparing for the 1.0 major release.
Many in the data streaming world know that there is no such thing as a pipeline that is always running. Most pipeline errors encountered are a result of temporary issues like network interruptions or services being unavailable due to maintenance. It then becomes a matter of how we handle the pipeline.
In most cases, simply retrying is enough to get through transient errors efficiently. This can and should be done by connectors and processors. But what if they don’t have a proper backoff implementation? For Conduit users, this typically means they would need to wait for the connector or processor to be updated. That’s where Conduit’s pipeline recovery comes in.
How does it work?
If a pipeline experiences an error such as a source connector cannot read a record or a processor fails to process a record, the pipeline is stopped and the status is set to degraded.
Pipeline recovery in Conduit v0.12 by default will restart the pipeline that experienced the error. However, you can always disable this feature if needed.
Conduit restarts a previously failed pipeline using a backoff algorithm for which the parameters can be tuned with CLI flags, environment variables, or a global configuration file. We’ll explain this behavior through the following scenario, assuming that the default backoff settings are used.
- A PostgreSQL-to-MongoDB pipeline starts.
- After some time, the source PostgreSQL instance becomes unavailable. This results in an error that causes the pipeline to stop.
- Conduit waits for 1 second and restarts the pipeline.
- The pipeline fails again because the source PostgreSQL instance is still unavailable. The waiting is multiplied by 2, so Conduit waits for 2 seconds.
- Step 4 is repeated until the pipeline is running. Maximum waiting time is 10 minutes.
Here's a diagram of the algorithm:
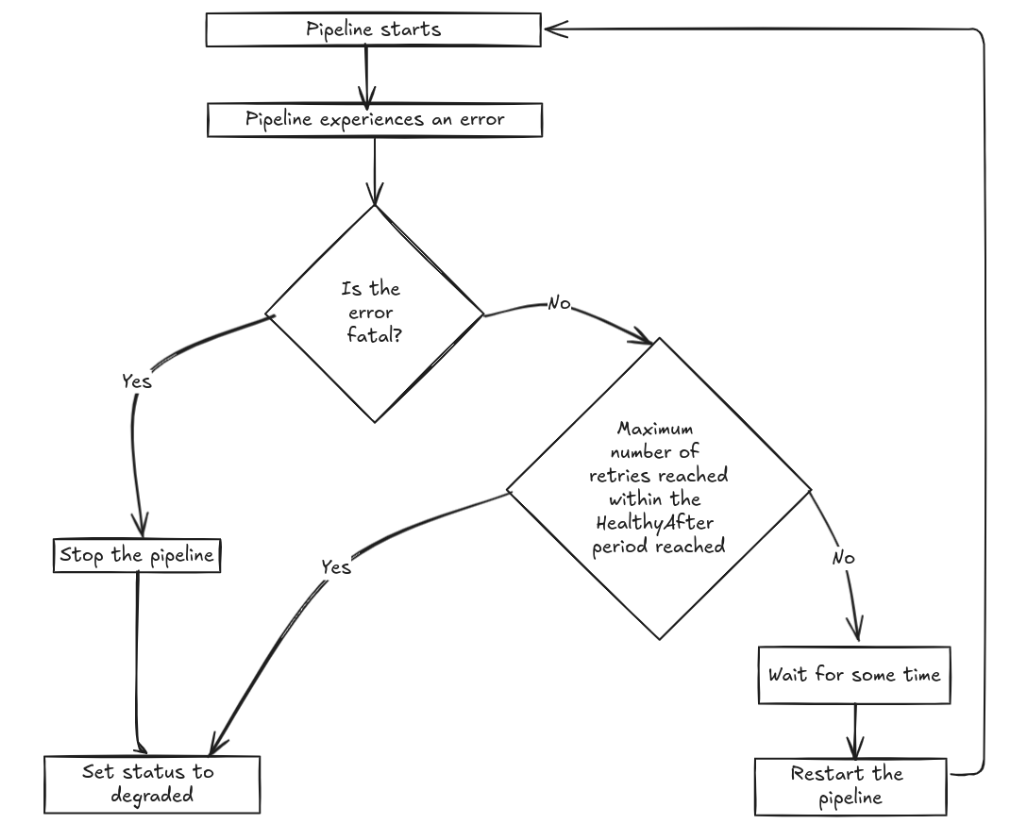
By default, there’s no limit on the number of retries. If the retries are limited, then Conduit will also make sure that the recovery attempts are reset smartly so that:
- Recovery attempts are not tracked indefinitely. That would cause, for example, a pipeline to transition into the
degradedstate because it failed 3 times in the past 12 months. - A pipeline is not being restarted indefinitely because it manages to start just before the maximum number of retries, and after some time, it fails again.
The documentation for pipeline recovery can be found here. As always, the Conduit team is happy to hear any feedback you might have about this feature! You can find us on our Discord server or you can start a new GitHub discussion!




